本記事を10秒でまとめると
Sakana AIが提供を開始したマルチエージェントAI「Fugu Ultra」を実際に利用し、ブラウザゲームの開発を依頼した。結果としてCPU対戦やチュートリアルを備えたアプリが完成しただけでなく、Fugu Ultraは自らコードレビューやテストを繰り返しながら開発を進めるという、これまでの生成AIとは異なる挙動を見せた。本記事ではFuguとは何か、どのように利用するのか、そして実際にアプリ開発で試した結果どうなったのかを詳しく紹介する。
今回の検証とは
2026年6月、AI INSIGHTでは最新の生成AIモデルを利用し、私と同年代にしか刺さらないであろうHUNTER×HUNTERに登場するボードゲーム「軍儀」を学べるブラウザゲームを作成する実験を行いました。
Claude Fable 5 / GPT-5.5 / Gemini 3.1 Proの3モデルに対して同じゲーム開発を依頼し、完成度を比較したところ短いプロンプトだけで比較した場合はClaude Fable 5が非常に高い完成度を見せた一方、本格的な要件定義を投入した場合にはGPT-5.5が実際に遊べるレベルのアプリを生成してくれました。

しかし、その後生成AI業界では新たなプレイヤーが登場しました。それがSakana AIの「Fugu」です。
SNSや開発者コミュニティでは、「複数のAIが協力して開発しているように見える」「自己レビュー能力が異常に高い」といった声も上がっているSakana Fuguの最高モデル:Fugu Ultra単体に焦点を当て、
「実際の開発業務を任せたらどこまでできるのか」
を検証することにしました。題材は前回と同じく軍儀です。複雑なゲームを作れるのであれば、業務アプリやWebサービス開発でも高い能力を発揮できる可能性が高いと言えます。
Fuguとは何か
Fuguは、日本発のAIスタートアップであるSakana AIが提供するマルチエージェントAIです。
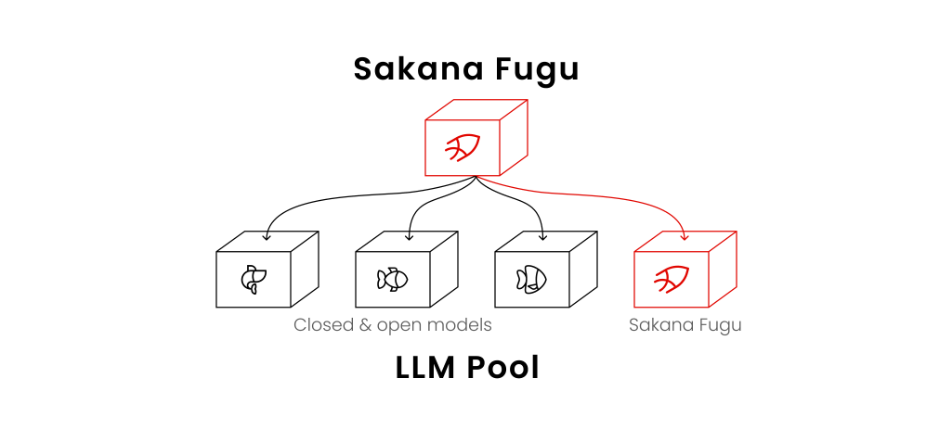
一般的なChatGPTやClaude、Geminiは、基本的には単一の大規模言語モデルがユーザーの指示に応答する仕組みになっています。もちろん内部的には様々な工夫が存在するが、利用者から見ると「1つのAIと会話している」感覚に近い状態です。
一方でFuguは発想が異なります。ユーザーからの指示に対し、複数のAIが役割分担を行いながら問題解決を行います。
例えば、
- 実装担当
- レビュー担当
- テスト担当
- 改善提案担当
のような役割を複数のエージェントが持ち、それぞれが協力しながら最終結果を作り上げるイメージが近いでしょう。
そのためFuguは単なるチャットAIというよりも、「小さな開発チーム」に近い存在とも言えます。
重要なのは、Fuguは単一モデルの性能を競うプロジェクトではないという点で、GPT-5.5やClaudeのような「どのモデルが最も賢いか」という競争ではなく、複数モデルやエージェントをどのように協調させるかという発想となります。
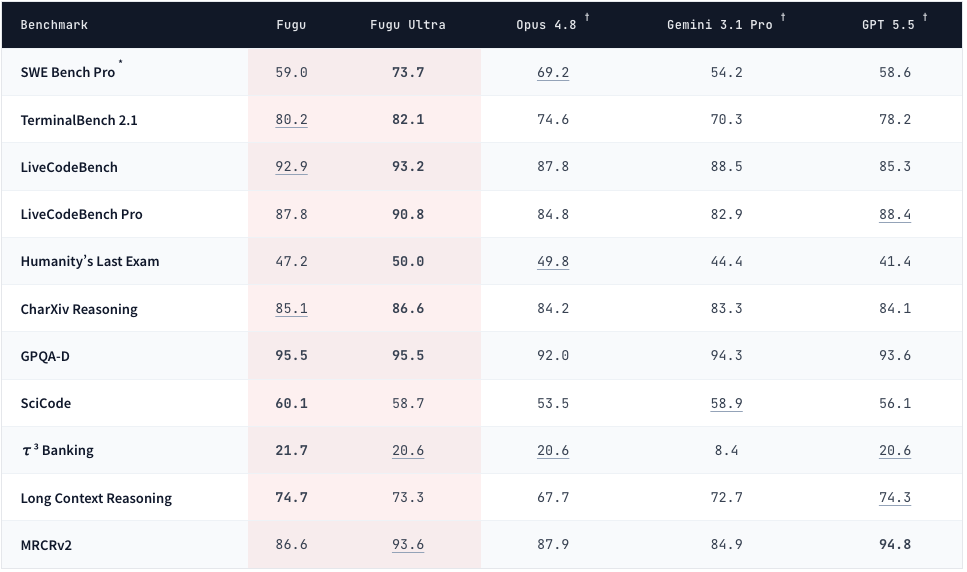
FuguとFugu Ultraの違い
現在提供されているモデルは大きく分けて2種類です。
まず標準モデルである「Fugu」。こちらは複数のプロバイダーを動的に利用しながら、速度と品質のバランスを重視したモデルです。日常利用や軽い開発作業であれば十分実用的。
そして上位モデルが「Fugu Ultra」。こちらはより複雑なタスクや長時間の開発作業を想定して設計されています。特にソフトウェア開発やコードレビュー、長時間エージェント実行などの用途を強く意識しています。
今回の軍儀アプリ開発では、このFugu Ultraを利用しました。
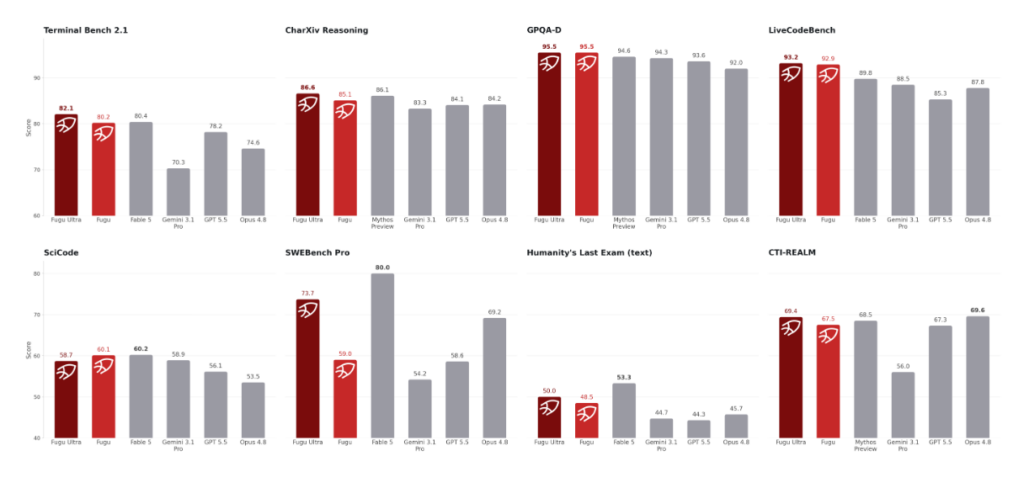
なぜ話題になっているのか
Fuguが注目されている最大の理由は、単純な回答精度ではありません。むしろ、「どのように仕事を進めるか」です。ChatGPTやClaudeが優秀な個人プレイヤーだとすると、Fuguは複数人の開発チームを仮想的に作り出しているようなもので、実際に利用してみると、「なぜその実装を選んだのか」「どこに問題がありそうか」「どのようにテストするべきか」といった開発プロセスそのものも多数出力されました。
単に答えを返すだけではなく、自分自身の成果物を検証し続ける点が、従来の生成AIとの大きな違いとなります。
Fuguの使い方
ではまず実際のFuguの利用方法から説明します。
料金プラン
Fugu / Fugu Ultraにはトークンプラン(従量課金制)とサブスクリプションプラン(月額定額制)が用意されています。
2026年6月時点では、サブスクリプションプランでは
- Standard(月額20ドル):個人利用や小規模な実験向け
- Pro(月額100ドル):継続的な開発や調査業務向け
- Max(月額200ドル):長時間のエージェント実行を想定したパワーユーザー向け
の3プランが提供されています。
今回の検証では最も安価なStandardプランを利用しました。
現在 2026 年 7 月末 までに登録すると、 加入したプラン の 2 か月目が無料 になるキャンペーン中です。
APIとして利用する
FuguはOpenAI互換APIとして提供されています。そのため、OpenAI SDKを利用している既存のアプリケーションでも比較的簡単に利用できます。クローズドモデルではなく単一APIで世界のトップモデル群を動的にオーケストレーションが出来るのがFuguの最大の魅力の一つです。
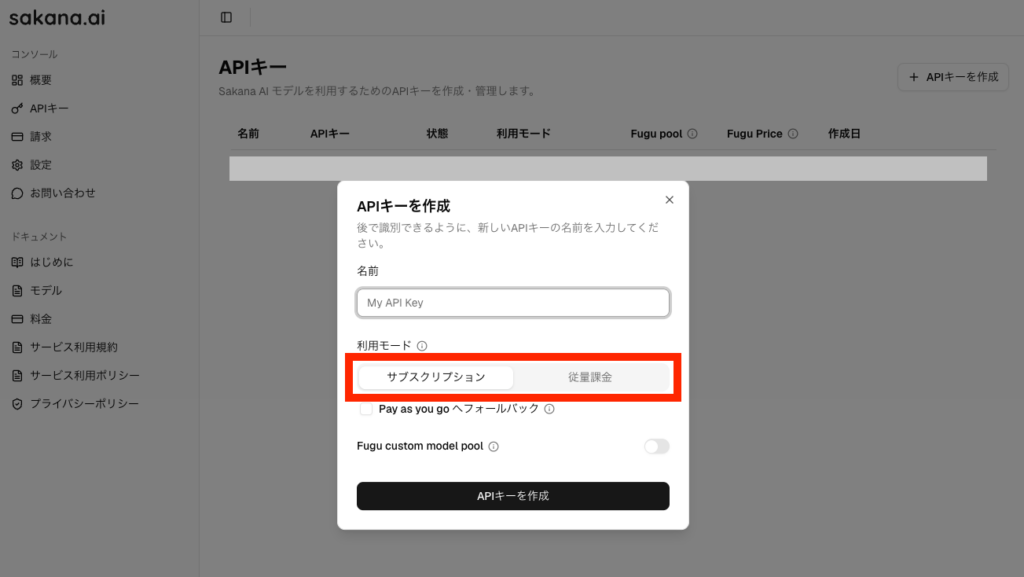
「https://console.sakana.ai/login」からログインとプラン選択すると管理コンソール画面に遷移するので、サイドパネルの「APIキー」から「APIキーを作成」を選択してまずはAPIキーを作成してください。
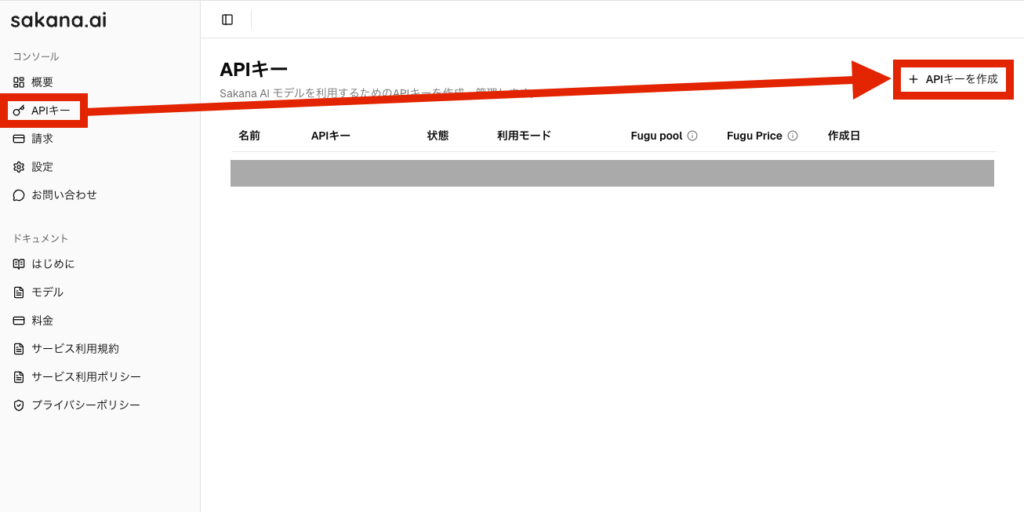
作成時に「利用モード」選択の画面がありますので、まずは「サブスクリプション」をお勧めします。
【余談1】Base URL
FuguはOpenAI互換APIとして提供されています。そのため既存のOpenAI SDKや各種エージェントフレームワークから利用可能です。従って、今回の検証ではAPIコードを直接書いていません。Sakana AIが提供するCodex連携を利用すると、Base URLの設定や接続設定は自動で行われます。
FuguをAPIから呼び出す場合は「https://api.sakana.ai/v1」をBase URLとして指定してください。
from openai import OpenAI
client = OpenAI(
base_url="https://api.sakana.ai/v1",
api_key=api_key
)【余談2】Colabでは思わぬ落とし穴も
筆者は最初Google Colabから利用しようと考えていました。しかし実際に試したところ403エラーが発生し、接続できなす大人しくローカル環境での検証に切り替えました。
今後の利用範囲がどう広がるかは不明ですが、現状は少なくともOpenAI 互換 APIとしてCodex経由では問題なく利用可能です。
Codexと接続する
Sakana AIが公式に提供しているCodex連携をしていきましょう。CodexはOpenAIが提供する開発向けAIエージェントです。ChatGPT以外利用したことがないという方もまだ多いかもしれませんが、Codexは一般的なチャットUIとは異なり、ファイル作成やコード編集、テスト実行といった開発作業を一貫して行えます。
もし利用端末にCodexをインストールされていない場合でも公式インストーラーを実行すればCodex本体も含めて自動セットアップされますのでターミナルを開き、以下のSakana AI公式インストーラーを実行してください。
curl -fsSL https://sakana.ai/fugu/install | bash実行すると、
- Codex CLI
- Fugu用モデル設定
- API接続設定
が自動的に構成されます。
セットアップ途中でAPIキーの入力を求められるので、先ほど作成したSakana APIキーを貼り付けるだけで設定完了です。
設定完了後は、
codex -p fuguまたは
codex -p fugu-ultraでそれぞれのモデルを起動できます。なお、起動直後はモデル選択画面が表示されます。fugu / fugu-ultra 好きな方を選択してください。
※2026年6月22日時点での公式ドキュメントに従っています。今後のCodexアップデートで変更になる場合があります。
簡単な相談や軽い作業であればFuguでも十分ですが、今回は長時間の推論含む開発をさせるのでFugu Ultraを選択します。
ここまで完了すればChatGPTやGeminiと同じように普通に会話するだけです。
なぜ軍儀アプリ開発で試したのか
今回の検証で軍儀を題材として選んだのには理由があります。軍儀はHUNTER×HUNTERに登場し、その後実際に商品化もされたボードゲームです。決して筆者がHUNTER×HUNTERファンというわけではなく、一見すると将棋やチェスに近いが、実際にはそれらよりも遥かに複雑な要素を持っていることが理由です。
例えば、
- 9×9の盤面
- 積み駒による高さ概念
- 特殊駒
- 手駒再配置
- 特殊ルール
- 初期配置戦略
などが存在します。さらに今回は前回同様、
- CPU対戦
- 初心者対戦
- チュートリアル
- ルール解説
- スマホ対応
- 保存機能
まで要求しました。単純なサンプルゲームを超えて実際に遊びながら軍儀を学べるアプリを目指します。
もしこのレベルのアプリを生成できるのであれば、業務システムや社内ツールなどの開発にも十分応用できることでしょう。そこで今回は、Fugu Ultraに対してかなり本格的な要件定義を投入し、その開発能力を検証します。
実際に軍儀アプリ開発を依頼
今回投入した要件は、一般的な生成AIのサンプル実験よりもかなり重く以下のような機能となります。
- 軍儀の基本ルール実装
- CPU対戦
- 初心者向け固定配置
- チュートリアルモード
- ルール解説
- スマホ最適化
- 保存機能
- 対戦ログ
さらに単一HTMLではなく、HTML / CSS / JavaScriptを適切に分割し、保守可能な構成にすることも要求しています。
ここまでは前回のGPT-5.5検証と同じですが、この後Fugu Ultraは予想していなかった行動を取り始めます。
なんと単にコードを書くだけではなく、自らレビューと検証を開始したのです。
Fugu Ultraの開発スタイルは予想外だった
実際に開発を開始して最初の数十分は、正直なところ他の生成AIと大きな違いは感じませんでした。要件を読み込み、
- index.html
- style.css
- app.js
- rules.js
- state.js
といったファイル群を生成しながら、少しずつアプリを組み上げていく。ここまではGPT-5.5やClaudeでも見られる一般的な開発プロセスです。しかし、あるタイミングから様子が変わり始めました。
突然、自分でコードレビューを始めた
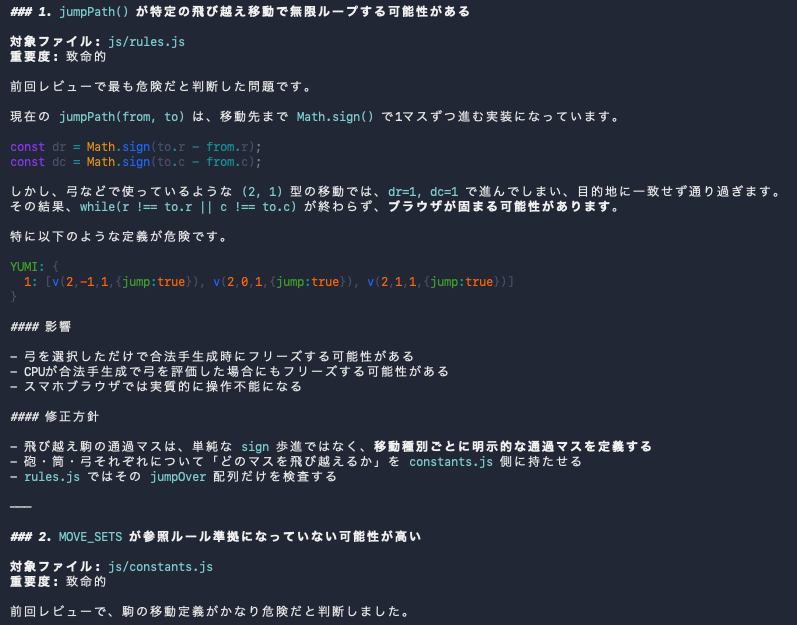
こちらから特別な指示を出していません。Fugu Ultraは、自ら生成したコードを読み返し始めたのです。そして次々と問題点を洗い出していく。
例えば最初に挙がったのが、移動処理に関する無限ループの可能性でした。
レビュー結果には、「特定の飛び越え移動で jumpPath() が無限ループする可能性がある」と記載されています。
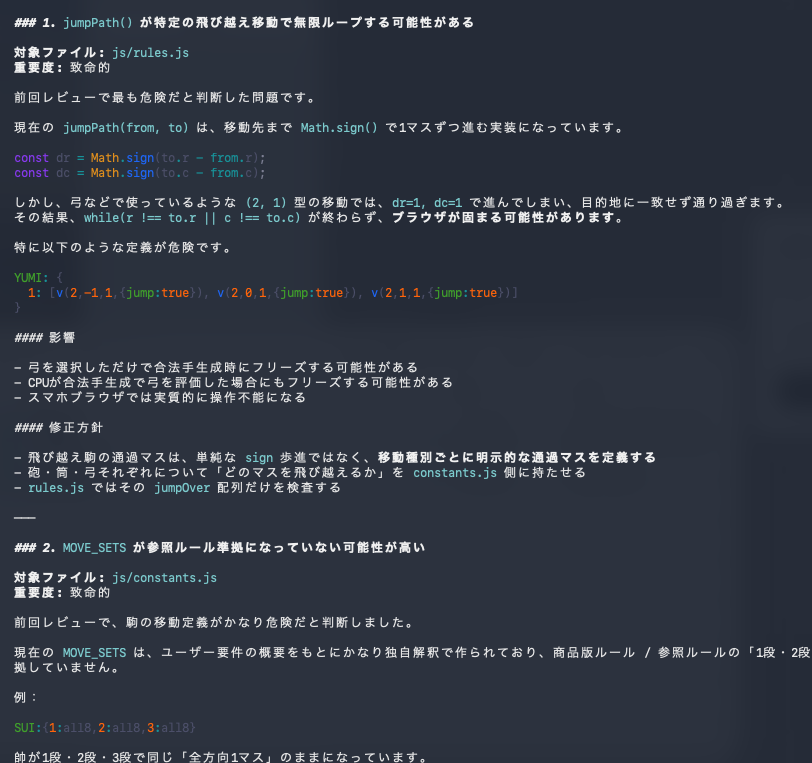
さらに、「ブラウザが固まる可能性がある」「CPU思考中にもフリーズする可能性がある」といったリスク評価まで付けられています。
単なるコードレビューではない。まさにレビュー担当者が別に存在しているような出力が出てきます。
ルールの不整合まで洗い出した
さらに驚いたのは、コードの品質だけではなく、ゲームルールそのものまで検証し始めたことです。
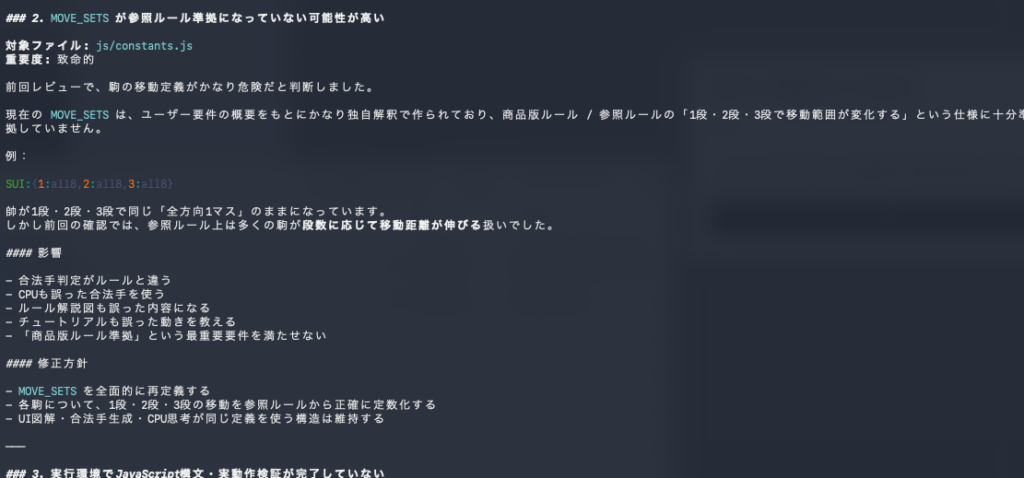
レビュー結果では、
- 駒移動定義が商品版ルールと一致していない可能性
- 特殊駒の挙動が曖昧
- 段数による能力変化の実装が不正確
など次々と自ら指摘し、リサーチした上で「MOVE_SETS を全面的に見直すべき」という指摘してきました。
普通の生成AIであれば、「動くコードを書いたので完成です」で終わるケースが多い中、Fugu Ultraは、「そもそもこのルール実装は本当に正しいのか」という観点で自己批判を行っていた。
これはかなり人間の開発プロセスに近く、今まで生成AIの最も苦手だったことの一つである自律的に自己批判を行い修正方針の整理まで行なっているのです。
自己レビューのレビューまで始めた
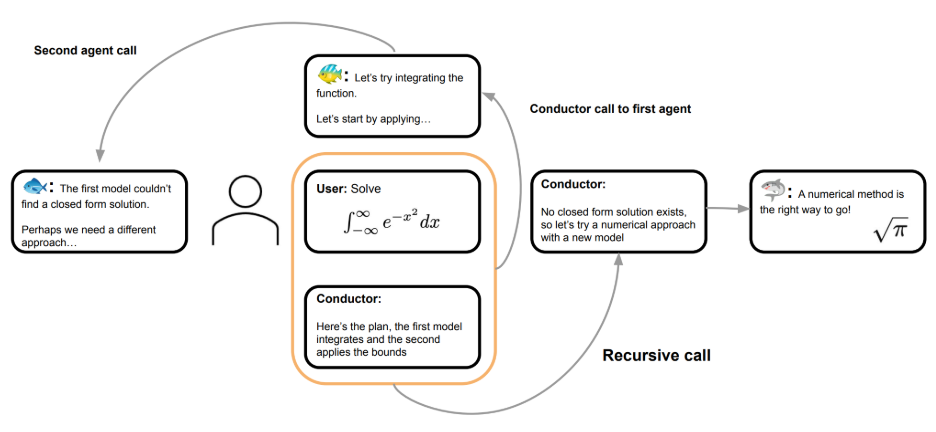
さらに面白かったのは、その後です。Fugu Ultraは自分自身が作成したレビュー結果を再度見直し始めました。例えば、「この指摘は推測に基づいている」「実際に動かして確認する必要がある」「ソースコードだけでは断定できない」といった修正を自らしていくのです。つまり、
実装
↓
レビュー
↓
レビューの検証
↓
レビュー内容の修正
というサイクルを自律的に行なっていたのです。
ここまで来ると、単なる生成AIではなく、sakana.aiが主張する「トップモデル群を動的にオーケストレーションし、複数ステップに及ぶ複雑なタスクを自動的に解決するAI」でありさながら「開発チーム」という見方の方が近いというのも頷けるでしょう。
テストコードまで作り始めた
なんとレビューだけでは終わらないのがFugu Ultra。次にFugu Ultraは「実際にブラウザで動作確認するべき」と判断し
- JavaScript構文確認
- ローカルサーバー起動
- 実機テスト
- 画面遷移確認
といったテスト計画を作成し始めます。途中で、「まだブラウザ確認が完了していない」「CPU対戦が正常動作する保証はない」など、まるで独り言のように自分で限界も説明していました。
この辺りは従来の生成AIではあまり見られなかった挙動です。
Standardプランはどこで限界が来たのか
今回の検証でもう一つ紹介したいのが、Fugu Ultraの性能だけでなく実際にどれくらい使うと利用上限に到達するのかという利用上限の目安です。
今回契約したのはは料金は月額20ドルの最も安価なStandardプランです。
1回目の利用上限
軍儀アプリ開発を開始して数時間後に1回目の利用上限が来ました。その時点での利用量は概ね以下となります。
- 入力トークン:約360万
- 出力トークン:約8万
- オーケストレーション入力:約50万
2回目の利用上限
利用制限解除はClaude同様5時間待つ必要があり、利用制限解除後に開発を再開。自己レビューやテスト実行を繰り返した結果、すぐに利用上限へ到達しました。その時点での利用量は以下のとおり。
- 入力トークン:約680万
- 出力トークン:約15万
- オーケストレーション入力:約90万
つまりStandardプランでも、かなり大規模な開発作業が可能だったことになります。
実際には想像以上に重い処理をしていた
Fugu Ultraの利用量を見ていて興味深かったのは、「オーケストレーション入力トークン」の存在です。API利用に慣れている方は通常のLLMでは、入力 / 出力だけを意識されているのではないでしょうか。しかしFugu Ultraでは、その裏側で複数のエージェントが協調動作しています。
その結果、ユーザーから見えない大量の推論処理が発生しているのです。今回も入力トークン約680万に対し、オーケストレーション入力が約90万トークン発生していました。内部でかなり複雑な処理が動いていることを示しています。
従量課金換算するといくらになるのか
Fugu Ultraの従量課金価格は、
100万トークンあたり
- 入力:5ドル
- 出力:30ドル
- キャッシュ入力:0.5ドル
となっています。
今回の検証規模を単純計算すると、入力だけでも数十ドル規模。さらに出力やオーケストレーション分も加えると、総額50〜100ドル前後の処理を実行していた可能性があります。
月額20ドルのStandardプランで1日でここまで試せたのは、かなりコストパフォーマンスが高いと言えるでしょう。
もっとも、大規模に毎日継続してこのような開発等を行わせる場合、Standardプランの20倍の利用枠があるMaxプランでも物足りない可能性が高く、トークンプランへの移行が必須となると推測します。
実際に完成したアプリ
そして最終的に完成したアプリがこちらになります。
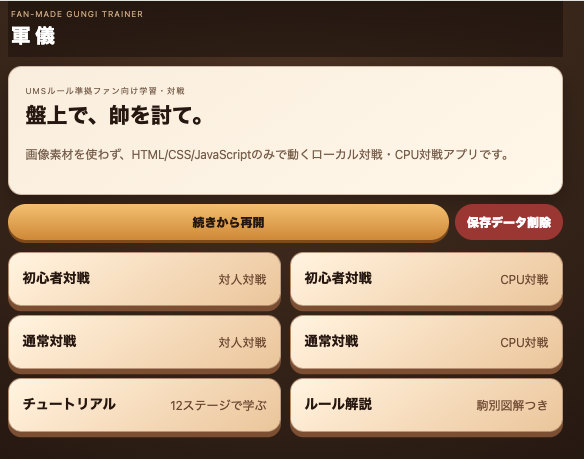
見て分かる通り、単なるモックアップではないブラウザアプリが生成されました。
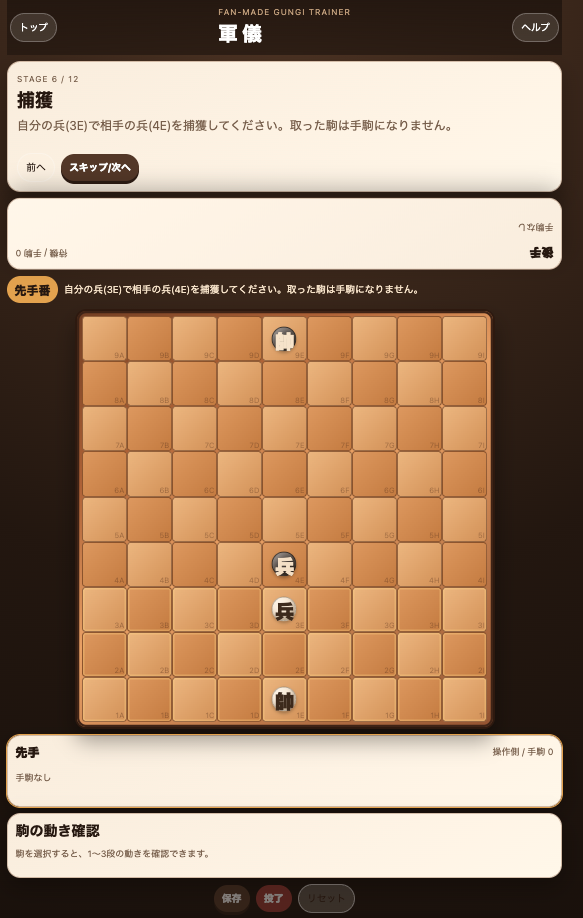
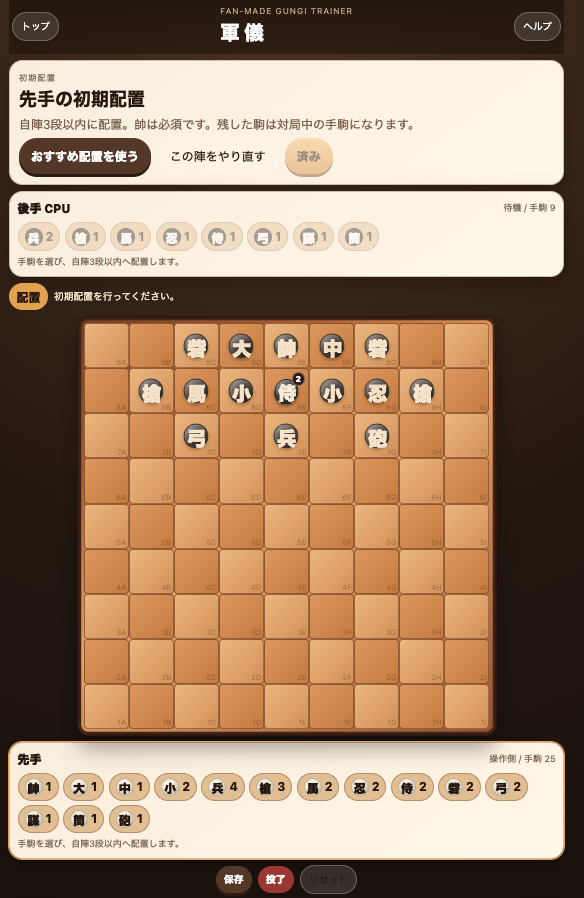
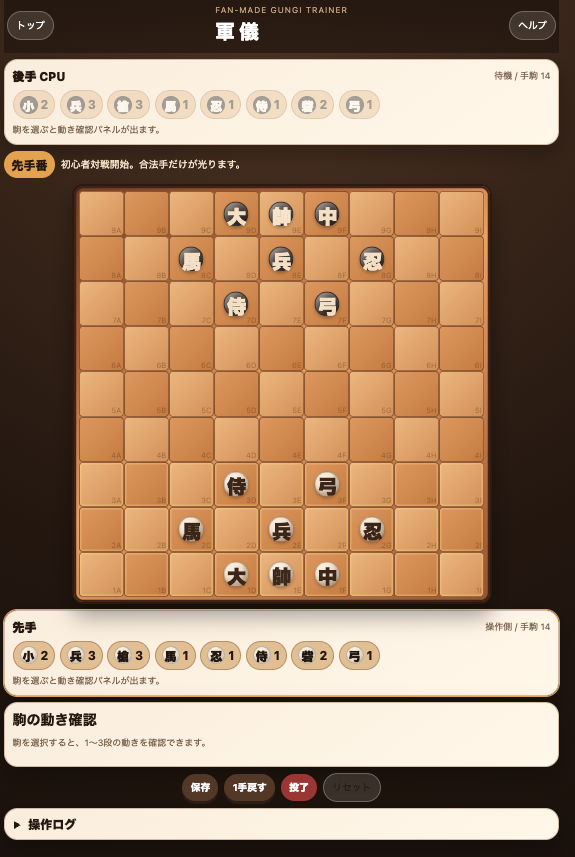
実際に、
- 対戦
- 駒配置
- 駒移動
- CPU応手
- チュートリアル
まで概ね問題なく動作しました。
もちろん商品版軍儀を完全再現したわけではなく細かい不具合は残ります。しかし、「軍儀を学ぶためのブラウザゲーム」としては十分成立しているレベルまで到達したと言えるでしょう。
以下に実際に作成したアプリを公開しておきますので、気になる方はご覧ください。
実際に触って分かった課題
もちろん課題も残っています。例えば、
- チュートリアル中に、「兵 兵」のような重複表示が発生する
- 一部チュートリアルで、「帥」が重複して表示される
- 対人対戦時に、先手・後手の手駒表示位置が想定と異なる位置に表示される
さらに言えば、ゲームとしては成立しているが、軍儀の商品版ルールを100%再現しているわけではなく特に特殊駒や細かな裁定については、今後も検証が必要です。
ただし重要なのは、これらが「遊べないレベルの致命傷」ではないという点です。実際に触った印象としては、過去に他モデルで作成したアプリよりも完成度は高いと言えます。
GPT-5.5と比較してどうだったか
では最後に前回勝者だったGPT-5.5と比べます。結論から言えば、完成品だけを見るならGPT-5.5の方が優勢だった印象です。
GPT-5.5は最初から比較的安定した構成を作り、大きな破綻も少なかった。一方でFugu Ultraは、開発途中で何度も立ち止まり、レビューし、修正し、テストする。そのため開発速度だけを見ると、むしろ遠回りしているようにも見えます。
しかし開発プロセス全体を見ると印象は異なり、GPT-5.5が優秀な個人開発者だとすれば、Fugu Ultraはレビュー担当とQA担当を含む小さな開発チームのようでした。
従って、ただ完成したアプリの出来で比較するべきではなく、生成AI自身が、「ここが危ない」「ここは未検証」「ここはルール確認が必要」と指摘し続けさながら優秀なエンジニアのように”思考”したことを評価すべきではないでしょうか。
そして今回はあえて追加で人間の修正を入れずに作成させましたが、本来であればこのオーケストレーションに人間が加わることで単一モデルを大きく超えた成果を創出できることは想像できるはずです。
まとめ
生成AIの進化というと、つい回答精度やベンチマークスコアに目が向く方も多いでしょう。しかしSakana Fuguの登場でマルチエージェントAIが目指している未来の一端を垣間見ることができたのではないでしょうか。
「生成AI群がどのように仕事を進めるか」「その生成AI群とどのように仕事を進めるか」が次の競争軸になることは避けられない事実です。
Fugu Ultraはまだ万能ではないかもしれません。ですがClaude Mythosの連携などにより今後さらに精度や安定性が向上すれば、単なるチャットAIではなく、実際の開発チームの一員として働く生成AIが現実になる日もそう遠くないのではないでしょうか。
さらに言えば、この大きな流れは開発の枠に捉われず全ての仕事におけるシンギュラリティとなる可能性を秘めていると私には思えてなりません。
writer:宮﨑 佑太