本記事を10秒でまとめると
国立情報学研究所が、日本語に強い大規模言語モデル「LLM-jp-4」シリーズを公開。約12兆トークンのコーパスで学習されたモデルで、一部の評価ではGPT-4oを上回る結果を示している。本記事では、日本語データ基盤やオープンモデル研究という観点で、日本の生成AI開発の現在地を示す。
国立情報学研究所が公開した「LLM-jp-4」
2026年4月3日、国立情報学研究所(NII)は日本語LLM研究コミュニティ「LLM-jp」の成果として、新たな大規模言語モデル「LLM-jp-4」シリーズを公開しました。
今回公開されたモデルは以下の2種類です。
LLM-jp-4 8Bモデル
- 約86億パラメータ
LLM-jp-4 32B-A3Bモデル
- 約320億パラメータ
- MoE(Mixture of Experts)構造
これらのモデルはオープンソースライセンスで公開されており、研究用途だけでなく実サービスへの応用も想定されています。また、最大で約6万5千トークンの入出力に対応し、日本語および英語の理解性能評価で高いスコアを示したとされています。
「LLM-jp-4」は待望の完全な国産LLMなのか
結論からいうと、LLM-jp-4シリーズは「完全な国産LLM」と言えるでしょう。
LLM-jp-4 8BがMetaのオープンモデル Llama系アーキテクチャ、LLM-jp-4 32B-A3BがAlibabaの Qwen系アーキテクチャをベースにしていると報道されており、NIIの公開している資料にも同様の表現がみられるものの、学習対象である重みについてはフルスクラッチで開発されているようです。
最も、モデル構造そのものをゼロから設計したわけではなく、既存のオープンモデルをベースに再学習・チューニングした形であったとしても、これは現在のLLM開発では珍しいことではありません。
実際、DeepSeekやRakuten AI、Sakana AIなど多くのプロジェクトも同様に、既存アーキテクチャをベースに学習データやチューニングで差別化しています。


どちらにせよ、今回のLLM-jp-4は「日本主導で開発された日本語最適化オープンLLM」と理解しておけば問題ありません。
今回のLLM-jp-4では、約12兆トークン規模のコーパスが使用されており、学習データは主に以下で構成されています。
- インターネット公開データ
- 政府・国会文書
- 多言語データ
- プログラムコード
- 合成データ
事前学習に使われたコーパスは約19.5兆トークンで、その中から最適化された約10兆トークン以上が学習に使用されています。
特に、日本語コーパスは約7000億トークン規模とされており、日本語LLM研究としてはかなり大規模なデータ基盤といえます。
GPT-4oを上回るベンチマークという結果
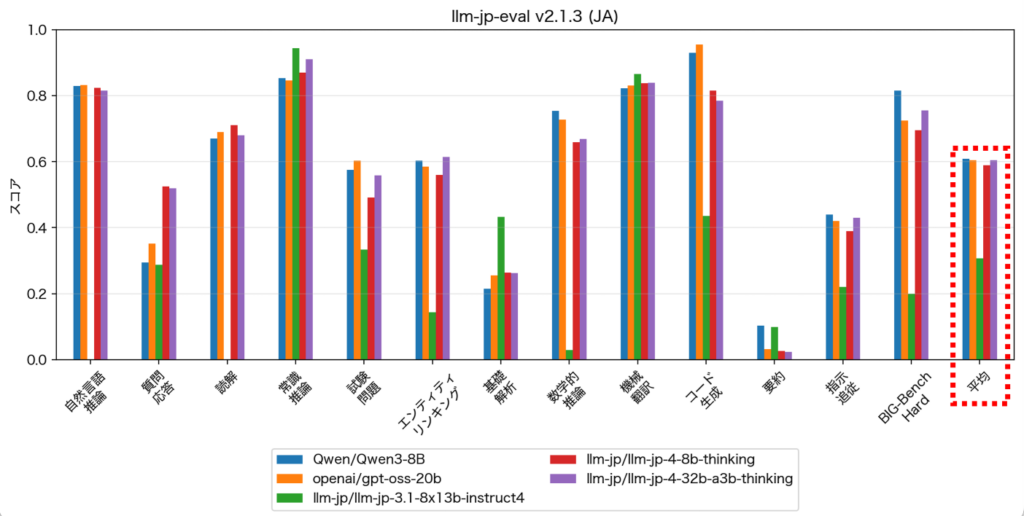
NIIの発表では、日本語理解性能を測る「日本語MT-Bench」で以下の結果が報告されています。
LLM-jp-4 8B:7.54
LLM-jp-4 32B-A3B:7.82
GPT-4o:7.29
Qwen3-8B:7.14
この結果だけを見ると、GPT-4oを上回る性能とされています。
ただし、ここには少し注意が必要です。
現在の生成AIの最前線は
- GPT-5系
- Claude 4系
- Gemini 2系
- DeepSeek V3
- Qwen3
といったモデルです。
そのため、GPT-4oとの比較は研究ベンチマークとしては意味がありますが、実運用レベルのフロンティアモデルと直接競合するわけではありません。研究評価と実サービスの性能比較は必ずしも一致しない点は理解しておく必要があります。
では、このモデルはどこに価値があるのでしょうか。大きく3点が考えられます。
① 日本語LLMの研究基盤
日本語の大規模コーパスや評価フレームワークを整備している点は、日本のAI研究にとって重要と言えます。
② オープンソース公開
モデル・データ・ツールが公開されることで、日本の研究者や企業がLLMを開発しやすくなります。
③ 日本のAIエコシステム
LLM-jpは2600人以上の研究者コミュニティで進められており、日本国内のAI研究ネットワーク形成にも寄与しています。
日本のLLM開発はどこまで来たのか
現在、日本でも複数のLLM開発が進んでいます。
本記事でも紹介したNIIのLLM-jpは研究主導における代表と呼べるでしょう。
その他国内企業主体であればSakana AI、Rakuten AI、NTT系LLMが挙げられます。
政府主導だとデジタル庁の「源内」プロジェクトを思い浮かぶ人もいるのではないでしょうか。

この記事が出る4月3日には、Microsoftが2026〜2029年に日本に100億ドルを投資する計画を発表しています。さくらインターネットとソフトバンクが協力し、国内AIインフラの選択肢拡充に向けたソリューションの共同開発についても検討が進んでおり、2社は Microsoft Azureからアクセス可能な日本国内のGPUを含むAI計算資源も提供していることから市場も盛り上がり株価がストップ高となっています。
一方で、世界を舞台に戦うOpenAI / Google / Anthropic / Alibaba等と比較するとそもそものモデル性能、マルチモーダル性、プラットフォームや各種SaaSとの連携性、エージェント機能どれをとっても太刀打ちできる状態ではありません。
少なくとも今はLLM-jpは「日本語LLMの研究基盤」という役割を担って入るものの、現状エンドユーザーの行動を帰るまでには至らないと言うのが正直な評価と言えます。
しかし、NIIは今後さらに大規模なモデルとして
- LLM-jp-4 32Bモデル
- LLM-jp-4 332B-A31Bモデル
の公開を予定しています。もしこれが実現すれば、日本発のLLMとしては最大級の規模になるため、今後の展望に期待したいところでもあります。
日本はなぜLLM開発で遅れ続けるのか
ここでやはり気になるのが、「なぜ日本のLLM開発は米国や中国に比べて遅れているのか」という点ではないでしょうか。
大きな理由は、主に3つあります。
まず1つ目は 計算資源の差です。
現在の最先端LLMは、数万〜数十万GPU規模の計算資源を使って学習されています。OpenAI、Google、Anthropicなどは巨大データセンターを持ち、数千億〜数兆円規模の投資を行っています。一方、日本ではこの規模の計算資源を国内企業が自前で確保するケースはまだ多くありません。
もっとも、日本に投資がないわけではありません。例えば、前述のMicrosofの投資や、ソフトバンクもAIデータセンター計画など大規模インフラ整備を進めています。
ただし、こうした投資の多くは AIインフラやクラウド基盤への投資であり、OpenAIやGoogleのように自社でフロンティアモデルを開発するための投資とは性質が異なります。
2つ目は 資金の使われ方の違いです。
米国ではOpenAIに対してMicrosoftが巨額の出資を行うなど、基盤モデルそのものの開発に直接資金が投じられています。中国でもAlibabaやByteDanceなどの巨大企業が自社LLMの開発を進めています。一方、日本ではAIインフラやクラウド整備への投資は増えていますが、世界最先端の基盤モデル開発に集中して資金が投じられるケースはまだ多くありません。
3つ目は データ基盤の差です。
LLMの性能は学習データの質と量に大きく依存します。英語圏はインターネット上の公開データ量が圧倒的に多く、中国でも国家レベルでデータ基盤整備が進められています。一方、日本語データは量が少なく、権利処理の問題もあり、大規模コーパスを構築する難易度が高いとされています。
こうした状況の中で、今回のLLM-jpプロジェクトは、日本語コーパスの整備や評価フレームワークの構築を進めており、日本のLLM研究基盤を整える取り組みとして重要な意味を持っています。
つまり、LLM-jp-4は世界最先端モデルと直接競争するプロジェクトというよりも、日本語AI研究の基盤を整備する役割を担っていると見ることができるのではないでしょうか。
まとめ
今回公開された「LLM-jp-4」は、日本語コーパスの整備やオープンモデル研究という観点では、日本の生成AI研究の重要な成果といえます。
世界ではOpenAIやGoogleなど巨大企業がLLM開発をリードし続けていますが、日本でも研究コミュニティ主導でLLM開発が進んでいることは事実です。
今後公開予定のより大規模なモデルが、国内ユーザーにどのような影響を与えるのか、引き続き注目していく必要があるでしょう。
writer:宮﨑 佑太(AI経営コンサルタント)