本記事を10秒でまとめると
大規模言語モデル(LLM)は英語での複雑な推論は得意だが、他の言語では性能が著しく低下することがカリフォルニア大学バークレー校の研究で判明。
単純なモデルの巨大化では解決せず、少量の翻訳データによる追加学習が有効であることも判明。
レポート「LONG CHAIN-OF-THOUGHT REASONING ACROSS LANGUAGES」*1
生成AIは、英語の質問に対しては、まるで人間のようにステップを踏んで複雑な問題を解決する能力(Chain-of-Thought)を示します。しかし、その能力が日本語やフランス語など、他の言語でも同じように発揮されるのかは、これまで十分に解明されていませんでした。
この論文は、LLMの多言語推論能力の限界と可能性を体系的に調査したものです。研究チームは、9つの非英語言語を対象に、モデルがどのように振る舞うかを3つの設定で比較しました。
- En-Only: 入力も推論もすべて英語(基準となる性能)
- En-CoT: 入力は対象言語だが、推論は英語で行う
- Target-CoT: 入力も推論も対象言語で行う
この比較を通じて、モデル開発の4つの側面(①モデル規模の拡大、②事前学習、③事後学習、④推論時のエラー)から、多言語推論能力の実態が明らかになりました。
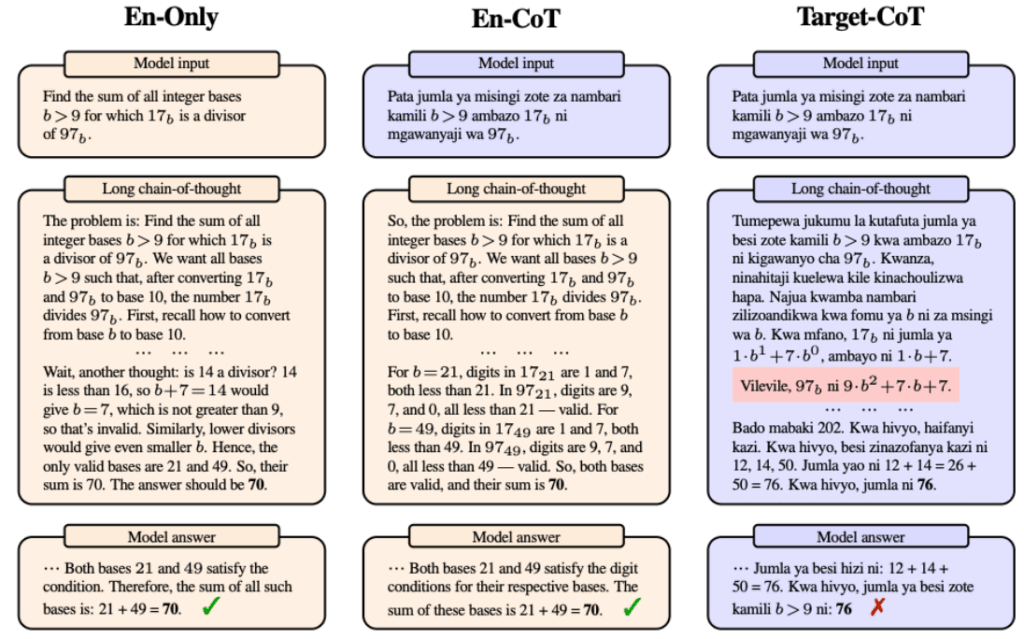
- 英語のみ(En-Only)、スワヒリ語入力・英語推論(En-CoT)、スワヒリ語入力・推論(Target-CoT)の比較。Target-CoTでは推論に誤り(赤枠)が生じ、不正解となっている。
発見1:モデルを大きくしても多言語推論能力は向上しない
今まで、一般的には「モデルは大きいほど賢い」と考えられてきました。しかし、多言語推論においては、この常識は誤りといえます。モデルのパラメータ数を増やしても、対象言語の「入力理解力」は向上するものの、対象言語で「思考する能力」はほとんど向上しなかったのです。
320億パラメータを持つ”高性能”なモデルが対象言語で推論する性能は、その4分の1以下の70億パラメータのモデルが英語で推論する性能にさえ及びません。これは、モデルの根本的な推論能力が英語に大きく依存していることを示唆しています。
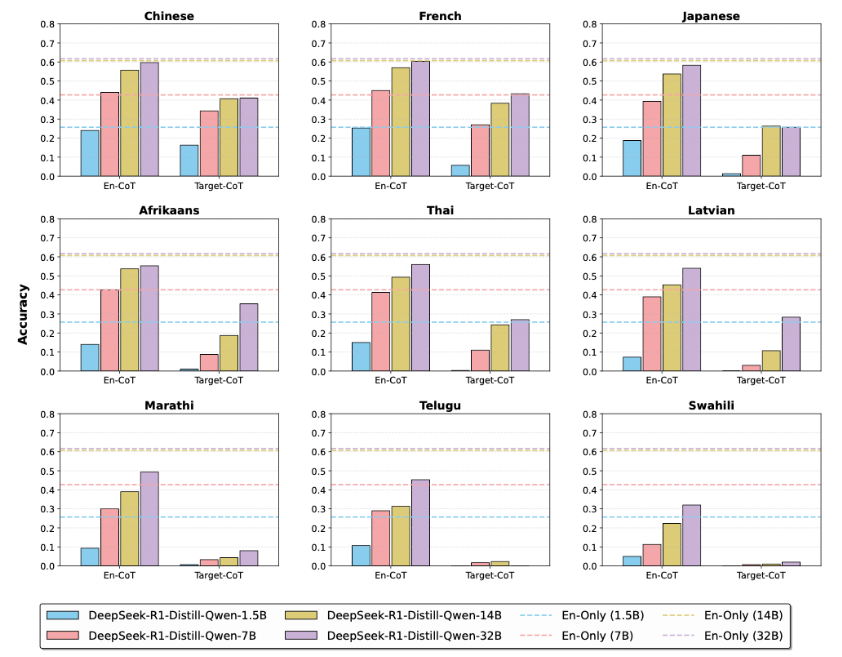
- モデル規模の拡大(Scaling)に伴う性能変化。En-CoT(左側)はモデル規模に応じて向上し英語(点線)に近づくが、Target-CoT(右側)は低迷したままであることがわかる。
発見2:英語偏重の追加学習はむしろ有害
次に、事前学習データの効果を検証したところ、幅広い多言語データで事前学習したモデルは、理解力と推論能力の両方が向上しました。
しかし、そのモデルに数学など専門的な英語の推論データを追加で学習させると、英語での推論能力は向上した一方で、対象言語での推論能力は逆に低下しました。専門知識を詰め込んでも、それが英語中心であれば、かえって多言語対応能力を損なう可能性があるということが判明しました。
発見3:「翻訳データ」による少量チューニングが極めて有効
英語以外の言語では、高品質な推論データがほとんど存在しません。そこで生成AI自身にデータを作らせる2つのアプローチを比較しました。
- 翻訳アプローチ: 既存の高品質な英語の推論データを各言語に機械翻訳する。
- 蒸留アプローチ: 生成AIに「日本語で考えなさい」と強制し、推論データを直接生成させる。
結果は「翻訳アプローチ」で作成したデータで追加学習したモデルのほうが、高い性能を示しました。特に、リソースの少ない言語では、わずか1,000件の翻訳データでの追加学習が、2万件の英語データで学習したベースラインモデルの性能を上回りました。
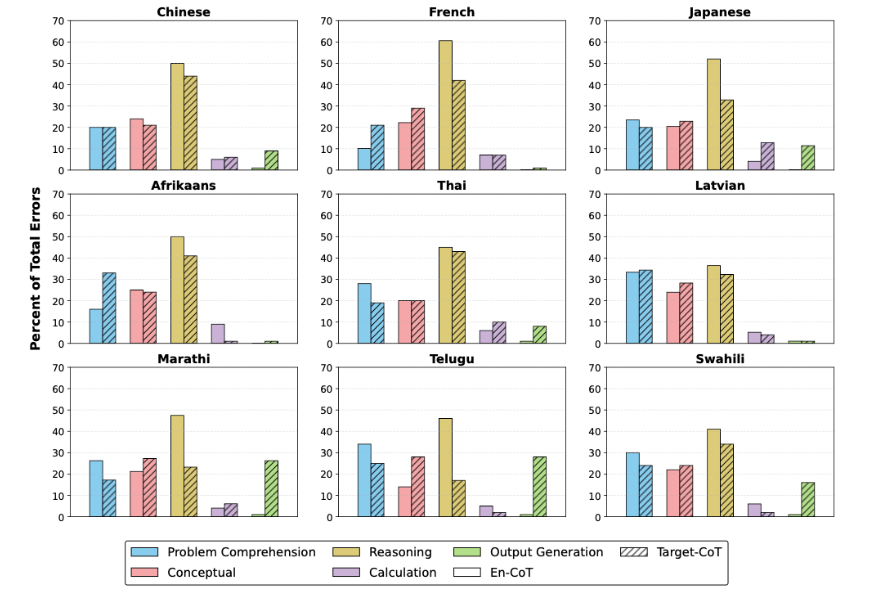
- エラータイプの分析。英語推論(En-CoT、白色の棒)では「Reasoning(推論)」の誤りが大半を占めるが、対象言語での推論(Target-CoT、網掛けの棒)では「Output Generation(出力生成)」や「Conceptual(概念理解)」のエラーが増加している。
結論
本研究は、LLMの高度な推論能力が、いかに英語という特定の言語に偏っているかを明らかにしました。モデルの規模拡大や英語中心の専門学習だけでは、この「言語の壁」は越えられません。
真にグローバルな生成AIを開発するためには、多言語データを活用した事前学習を基礎とし、さらに各言語に特化した「翻訳データ」によるファインチューニングを施すという、言語ごとの地道な取り組みが不可欠ということが判明しました。
英語での成功体験をそのまま他言語に持ち込むだけでは、見せかけの流暢さに騙され、肝心な思考力を見誤るリスクがあると言えるでしょう。
まとめ:ビジネスパーソンへの示唆
この研究結果を、ビジネスシーンで生成AI活用する際に活かすとするならば
- 「流暢さ」と「思考力」を混同しない
生成AIが流暢な日本語で応答したとしても、その裏側で実行されている思考の質が、英語の場合と同等であると期待してはいけません。特に、複数のステップを要する複雑な市場分析や戦略立案のようなタスクを日本語で依頼した場合、英語で依頼するよりも単純な間違いや論理の飛躍が起こる可能性があります。 - 重要なタスクでは「英語での思考」を検討する
非常に重要な意思決定を行う際など、生成AIの推論能力を最大限に引き出すためには、あえて一度英語で問題を整理させ、その思考プロセスと結論を日本語に翻訳させる、という使い方が有効です。 - 「自社データ(日本語)」による追加学習の価値を再認識する
自社の日本語マニュアルや過去の議事録、報告書など、質の高い日本語データを用いて生成AIをファインチューニングすることは推論精度をあげる上で大変重要です。生成AIをそのまま使うのではなく、自社の文脈に合わせて「日本語で正しく思考する能力」を鍛えることで、競合に対する大きな優位性を築ける可能性があります。
AIインサイトをご覧の皆様にとっては繰り返しになりますが、この論文は生成AIの出力を鵜呑みにせず、その思考プロセスにまで目を向けることが重要であることの裏付けになっています。
特に多言語環境で生成AIを活用する際は、言語によって生成AIの「隠れた実力」が大きく異なることを前提に、より慎重な検証と人間による最終判断が不可欠となるでしょう。
writer:宮﨑 佑太(生成AIアドバイザー)
*1:Long Chain-of-Thought Reasoning Across Languages (October 9, 2025) Josh Barua, Seun Eisape, Kayo Yin, Alane Suhr (University of California, Berkeley)