本記事を10秒でまとめると
ゲーム生成能力でも話題になったClaude Fable 5を、GPT-5.5、Gemini 3.5 Proと同じ条件で比較してみた。短いプロンプトだけでゲームを作らせる実験ではClaude Fable 5が最も完成度が高く、GPT-5.5が続いた。一方で、本気の要件定義を投入した実験ではGPT-5.5が実際に遊べるレベルの軍儀アプリを生成。Gemini 3.5 Proは途中で実装の簡略化が目立ち、完成度に大きな差が生じた。
今回の実験
何かと話題のAnthropicの新モデル「Claude Fable 5」がゲーム生成分野でも大きな注目を集めています。

SNS上では、「数分でゲームが完成した」「プログラミング知識なしでも遊べるゲームが作れた」といった報告も多く見られます。
そこで今回は、
- Claude Fable 5
- GPT-5.5
- Gemini 3.5 Pro
の主要生成AIツールの中でも最新3モデルを対象に、同じゲーム開発を依頼し比較検証を行いました。
題材として選んだのは、HUNTER×HUNTERに登場し、その後実際に商品化もされたボードゲーム「軍儀」です。
軍儀は将棋やチェスと比較してもルールが複雑で、
- 9×9盤面
- 積み駒
- 特殊駒
- 駒ごとの独特な移動
- 手駒の再配置
などを持っています。
ゲーム生成能力を測る題材としては非常に適しているのではないでしょうか。
第1戦:短いプロンプトだけでゲームを作らせる
まずは生成AIの素の能力を見るため、できる限り短いプロンプトだけでゲーム生成を依頼しました。
HUNTER×HUNTERに登場するボードゲーム「軍儀」を知らない人が、遊びながらルールを理解できるブラウザゲームを作成してください。 対象は軍儀未経験者です。 ルール説明だけではなく、実際に操作しながら自然に学べることを重視してください。 HTML・CSS・JavaScriptのみで実装してください。細かな仕様書や要件定義は渡していません。
実際に生成された画面がこちらです。
【Claude版スクリーンショット】
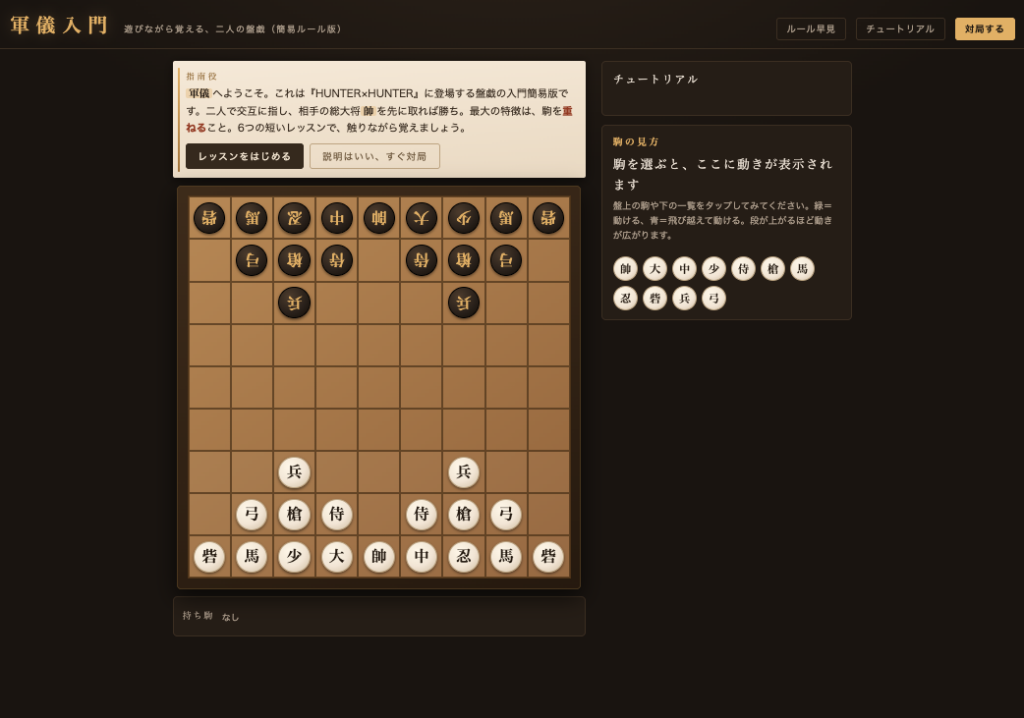
【GPT版スクリーンショット】
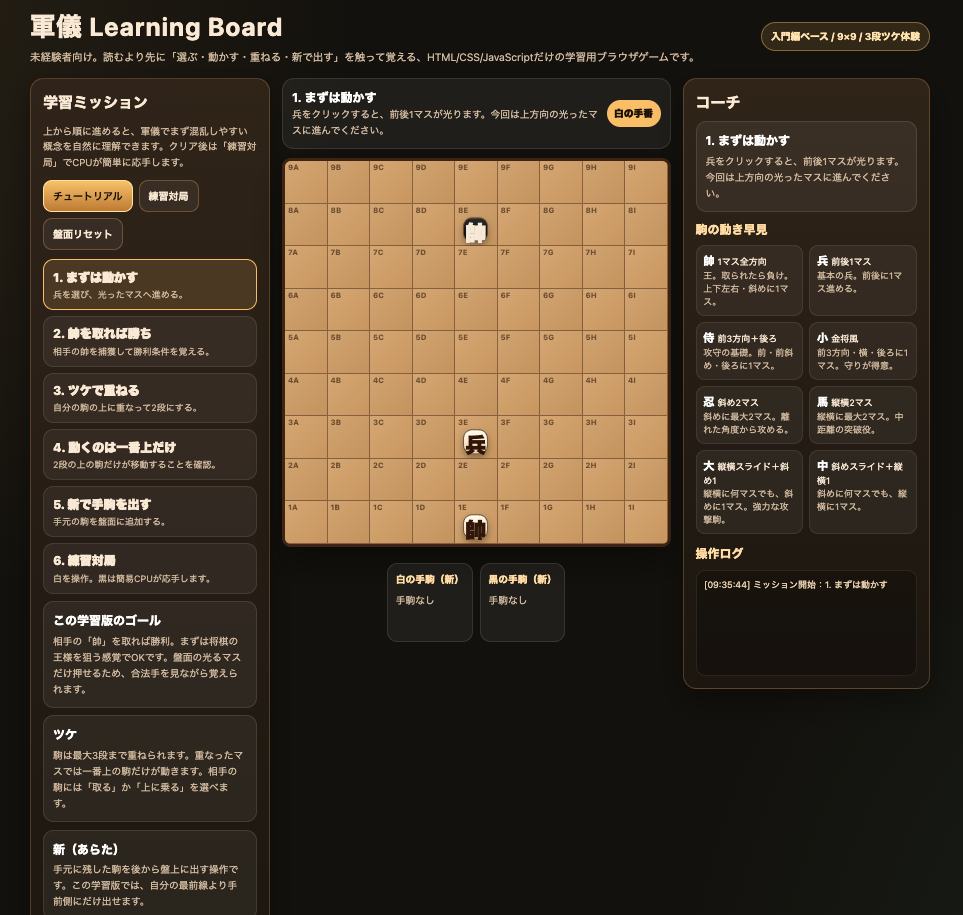
【Gemini版スクリーンショット】

実際に比較してみると、それぞれかなり性格が異なりました。
Claude Fable 5はUIデザインが非常に優秀で、学習導線やチュートリアル設計も自然です。未経験者向けゲームとして完成度が高く、「遊んでみたい」と思わせる力がありました。
GPT-5.5はUI面ではClaudeに及ばないものの、ゲームとして成立させようとする意識が強く、堅実な作りになっています。
一方のGemini 3.5 Proは最低限のゲーム構造は作れているものの、UI・導線・完成度の面では大きく差がありました。
短いプロンプトだけで比較すると、Claude Fable 5 > GPT-5.5 > Gemini 3.5 Proという印象です。
以下に実際に作成したアプリを公開しておきますので、気になる方はご覧ください。
第2戦:本気の要件定義を投入
次に、「実際の開発現場」を想定した検証を行いました。
今回作成した仕様には、
- 商品版軍儀ルール
- 初心者対戦
- 通常対戦
- CPU対戦
- チュートリアル
- ルール解説
- 保存機能
- 操作ログ
- スマホ最適化
- UIデザイン
などを含めています。
もはや単なるサンプルゲームではなく、実際に遊べるアプリを目指した内容です。
まさかの展開:Fableが利用不能に
本来はClaude Fable 5もこの検証に参加予定でした。しかし検証途中で利用できなくなってしまい、第2戦は実施できませんでした。

そのため本気の要件定義勝負については、
- GPT-5.5
- Gemini 3.5 Pro
の2モデルで比較しています。
GPT-5.5は実際に遊べる軍儀アプリを生成
GPT-5.5が生成したアプリがこちらです。

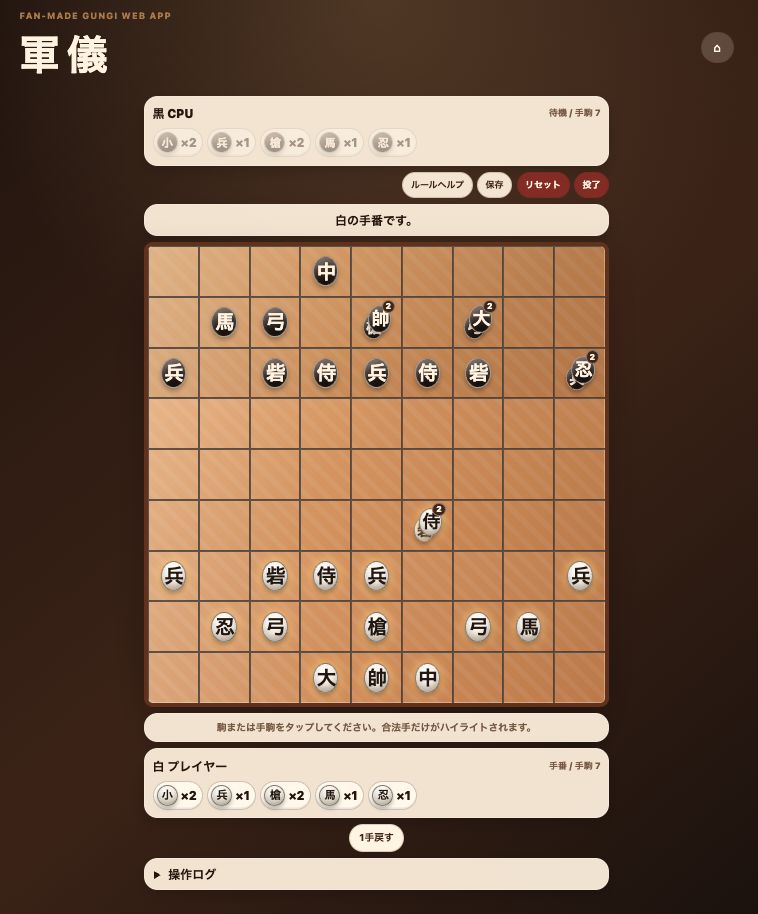
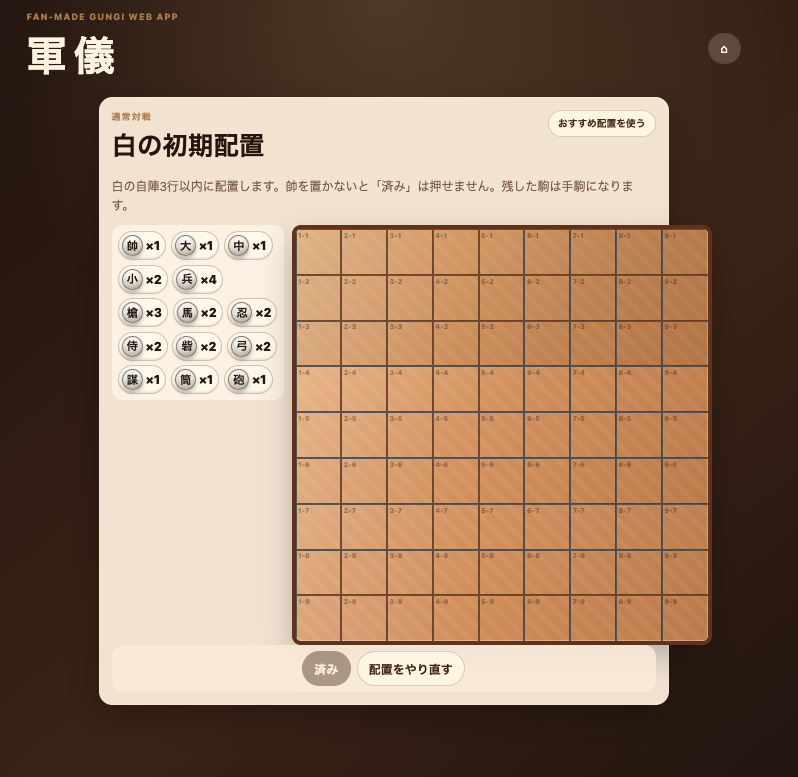
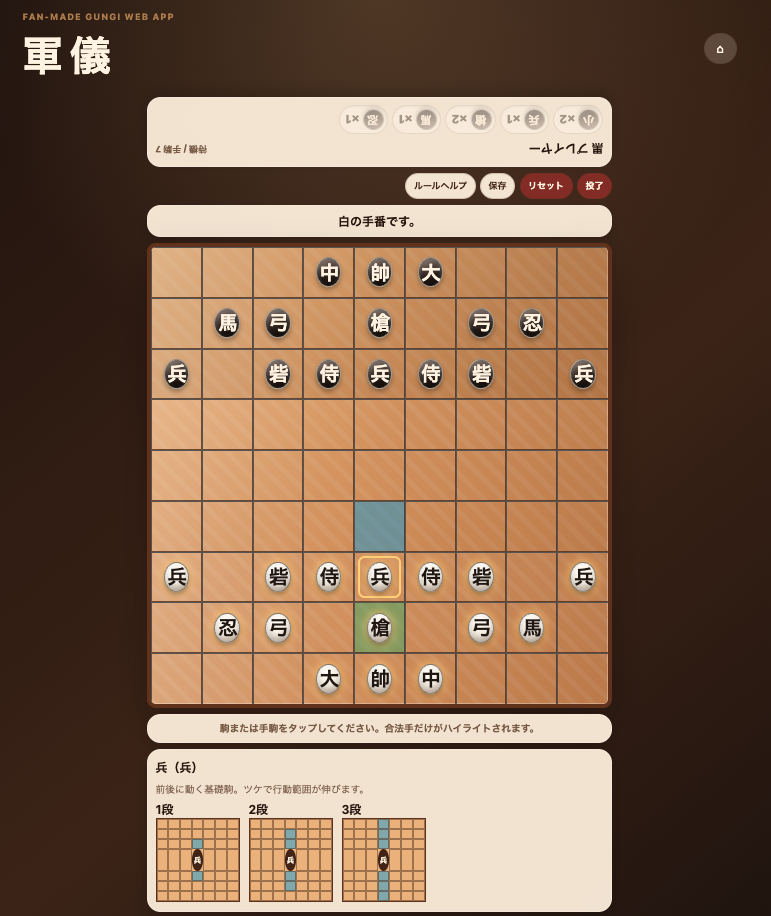
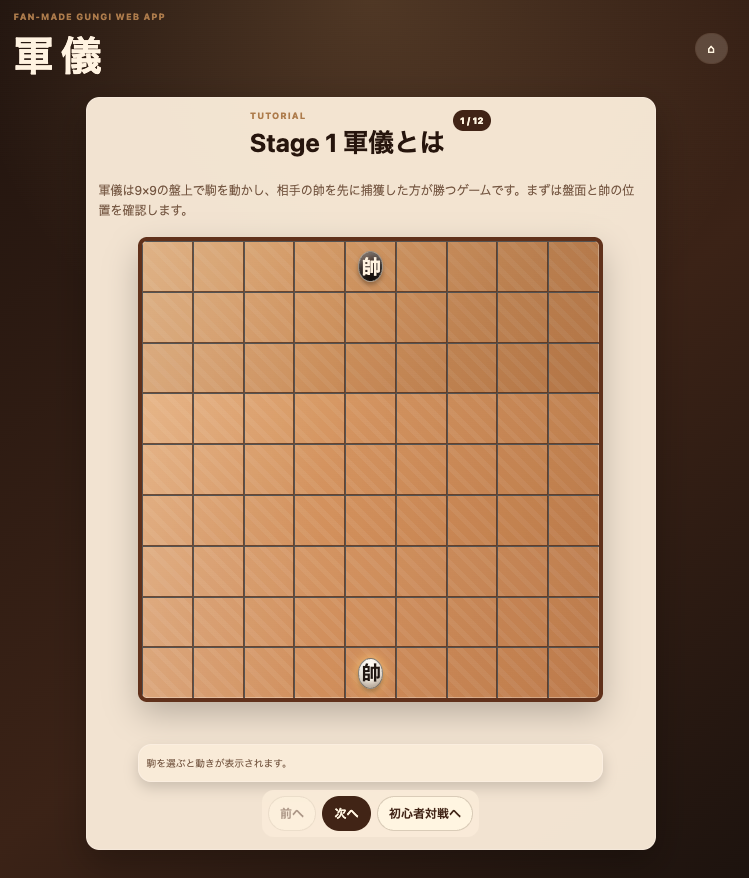
見て分かる通り、単なるモックアップではありません。
- CPU対戦
- 初心者対戦
- 通常対戦
- チュートリアル
- ルール解説
まで実装されています。
もちろん細かな不具合やルール解釈の違いは残っています。
それでも、要件定義からここまで到達できたことには正直驚かされました。
以下に実際に作成したアプリを公開していますので、是非軍議を学び、遊んでみてください。
Gemini 3.5 Proはなぜ苦戦したのか
Gemini 3.5 Proも要件自体は理解しているように見えました。
しかし実装量が増えるにつれて簡略化が発生し、
- 一部機能未実装
- ファイル構造の不整合
- UIの崩れ
などが目立つ結果となりました。
最終的には正常に動作するところまで到達できず、今回の検証では大きく差がつきました。
まとめ
今回の結果をまとめると、短いプロンプトだけで比較した場合はClaude Fable 5が最も印象的でした。
一方で、本格的な要件定義を伴う開発になるとGPT-5.5もかなり安定性がありました。Gemini 3.5 Proも今後の進化には期待できますが、今回の検証ではやや苦戦した印象です。もしClaude Fable 5がまだ利用可能であればGPT-5.5を超えるのか、そのままリリースできるほどのものが作れるかどうか実証実験できなかったことが悔やまれます。
ここでの学びは、「どのモデルが最強か」という話だけではなく、「細かく要件定義を行えば、モデル性能の序列を超えて良いものを作れる」ということではないでしょうか。
実際に簡易的なpromptでClaude Fable 5で作成したものよりも、詳細に要件定義したpromptでGPT-5.5が作成したものの方が操作性/視認性も高くバグも少なくなっています。
これはアプリ開発に限らず、ビジネスにおける様々な作業でも同様です。
モデル性能に頼りきらず、実行させたい事柄を詳細に生成AIと整理してから実行させるという流れを是非身につけてみてはいかがでしょうか。
writer:宮﨑 佑太