本記事を10秒でまとめると
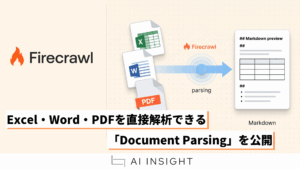
Firecrawlは、Excel・Word・PDFなどのドキュメントをURLから直接解析し、構造を保ったままMarkdownとして取得できる「Document Parsing」機能を公開した。PDFはOCRにも対応しており、テキストPDFだけでなくスキャン文書の解析も可能。これにより、LLMやAIエージェントが企業のドキュメントデータを直接理解する基盤としての活用がさらに進む可能性がある。
Firecrawlとは何か
Firecrawlは、LLMやAIエージェント向けのWebスクレイピング・データ取得ツールです。
AIが理解しやすい形でWebページを取得・構造化することを目的としており、LLMアプリケーションの開発者の間で広く使われています。
これまでFirecrawlは主に
- Webページのスクレイピング
- HTMLからMarkdownへの変換
- サイト全体のクロール
などを提供してきました。
今回新たに公開されたのが、Webページだけでなく「ドキュメントファイル」も直接解析できる機能です。

Excel・Word・PDFをURLから直接解析
新しいDocument Parsing機能では、以下のファイル形式に対応します。
Excel(.xlsx / .xls)
Excelファイルは以下のように処理されます。
- 各シートをHTMLテーブルとして変換
- シート名はH2見出しとして出力
- セルのデータ型やフォーマットを保持
例えば複数シートのExcelは、次のようなMarkdown形式になります。
## Sheet1| Name | Value |
|------|------|
| Item1 | 100 |
| Item2 | 200 |## Sheet2| Date | Description |
|------|-------------|
| 2023-01-01 | First quarter |
これにより、LLMが表データをそのまま理解できる形で取得できます。
Word(.docx / .doc / .odt / .rtf)
Word文書は、文書構造を保ったまま抽出されます。
保持される要素は以下です。
- 見出し
- 段落
- 箇条書き
- 表
- 基本的な書式
これにより、単なるテキスト抽出ではなく、ドキュメントの構造を理解した状態でLLMに渡すことが可能になります。
PDF(OCR対応)
PDFについては以下の特徴があります。
- レイアウト情報を保持
- セクション構造を維持
- OCRによるスキャンPDF解析
PDFは解析モードを選択できます。
| モード | 内容 |
|---|---|
| fast | テキストPDFのみ解析(高速) |
| auto | テキスト抽出+必要に応じOCR(デフォルト) |
| ocr | 全ページOCR |
例えばスキャンされた紙資料も、OCRを強制することで解析可能です。
URLを渡すだけで自動解析
Firecrawlの特徴は、ドキュメント解析も特別な処理なしで動く点です。
URLを指定するだけで、ファイル形式を自動判定し解析されます。
例(Node.js)
const doc = await firecrawl.scrape('https://example.com/data.xlsx');
取得された内容は、すべて構造化Markdownとして返されます。
まとめ
この機能が重要なのは、単なるファイル解析機能ではありません。
最近の生成AI市場においてユーザーのリテラシーが問われる要素の一つがコンテキストエンジニアリングです。
ユーザーにとって当たり前でも生成AIが理解できていない可能性が高い企業ドキュメントの理解。
実際の企業データはExcelやWord、pdfや紙媒体など様々な形式で保存されており非構造化データがほとんどです。
FirecrawlのDocument Parsingは、これらをLLMが理解できるMarkdownに変換するレイヤーとして機能します。つまり、AIエージェントが企業ドキュメントを直接読むための基盤として位置づけられる技術と言えるでしょう。
Firecrawlの今回のアップデートは、AIエージェント時代のドキュメント処理基盤の一つとして注目されそうです。