本記事を10秒でまとめると
GPT-5.2 Proは、単なる「性能向上モデル」ではありません。複数の実務的思考テストを通じて明らかになったのは、要件保持・自己修正・最小編集・失敗設計・期待値制御という“実務で壊れない思考様式”を獲得した生成AIであるという点です。
本記事では、5つの思考耐性テストを用いてGPT-5.2 Pro / GPT-5.2 / GPT-5.1 / Gemini 3 Pro を比較し、なぜGPT-5.2 Proだけが「考える相棒」として成立し始めたのかを解説します。
なぜ今「GPT-5.2はすごい」だけでは足りないのか
OpenAI社のコード・レッド発令の頃から新たなGPT-5.2における、数学・科学・推論系ベンチマークの数値が話題になっていました。確かに、これらの数値だけを見ると、GPT-5.2は「ほぼ完璧な生成AI」に見えます。しかし「ベンチマーク性能と実用性は別物である」という問題も認識しておく必要があります。
参考:OpenAI、緊急事態「コード・レッド」を宣言――Gemini 3の脅威と生成AI覇権戦争の新局面

参考:【ChatGPT】GPT-5.2時代のAIモデル選択論:ベンチマークの罠と実用性のギャップ

実務で生成AIが失敗する典型パターンは、ほぼ決まっています。
- 前提条件や制約を途中で忘れる
- 自分の出力を疑えない
- ダメ出しされると作り直してしまう
- 失敗を偶然扱いし、再発防止ができない
- 期待値を上げすぎて、現場や経営の信頼を失う
これらは、性能ではなく思考様式の問題です。
そこで本記事では、「実務で壊れない生成AIとは何か?」を検証するために、5つの思考耐性テストを実施しました。
今回の検証方法:5つの思考耐性テスト
今回の比較は、正解が一つに定まるタスクではありません。あえて以下のような、人間の思考が破綻しやすい状況を選びました。
- 制約が多く、利害が絡む
- 正解がなく、判断が必要
- 失敗や否決が前提にある
- 相手(経営・現場・顧客)の期待値調整が必要
その上で、以下の5つの観点で各モデルを評価しました。
思考耐性テストの5要素
- 要件保持力
複数の前提・制約を最後まで維持できるか - 自己修正力
自分の結論を条件付きで疑い、再評価できるか - 編集・最小修正力
作り直さずに「通る形」に直せるか - 失敗構造理解力
失敗を偶然でなく構造として説明できるか - 期待値制御力
全てを肯定せず、場合によっては意図的に期待値を下げられるか
※いずれも定量ベンチマークではなく、同一条件・同一プロンプトによる実務思考テストです。
5つの思考耐性テスト結果要約
ここでは詳細な出力比較は行いません。
ポイントだけを簡潔にまとめます。
- 要件保持力
GPT-5.2 Proは、多層制約を最後まで落とさず維持しました。 - 自己修正力
GPT-5.2 Proのみが、自分の結論を条件付きで自然に否定しました。 - 編集・最小修正力
GPT-5.2 Proは「作り直し」ではなく「最小修正」を選びました。 - 失敗構造理解力
GPT-5.2 Proは、失敗を構造・分岐点・介入点として整理しました。 - 期待値制御力
GPT-5.2 Proは全肯定を防ぐ説明が可能でしたが、
政治的・感情的配慮では人間に及ばない場面もありました。
この結果を視覚化したものが、次の図です。
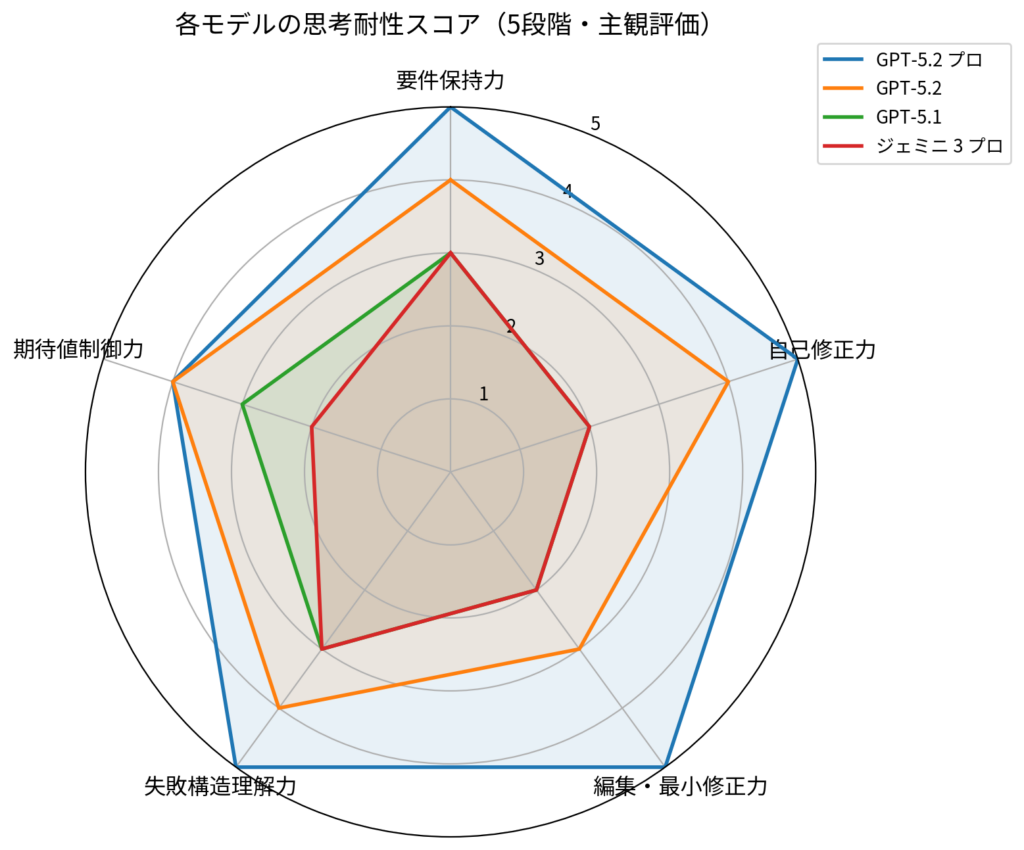
※この評価は、実施した思考耐性テストに基づく主観評価です。
テスト①:多層制約下での提案設計(要件保持力)
【テスト内容】
以下のような 実務でありがちな“制約だらけの提案依頼”を与えました。
- 業界・企業規模・期間・数値目標
- セキュリティ制約(クラウド不可 等)
- 現場反発・経営視点の両立
- 助成金や制度要件
- 出力形式の指定(構造・粒度)
【評価観点】
- 途中で制約を落としていないか
- 後半で前提を“勝手に書き換えて”いないか
- 全体として矛盾がないか
【観測された違い(要約)】
- GPT-5.2 Pro:全制約を最後まで保持。想定質問まで先回り
- GPT-5.2:大枠は保持するが、一部制約が弱まる
- GPT-5.1 / Gemini 3:後半で条件落ち・一般論化が発生
テスト②:自己主張 → 自己否定 → 再評価(自己修正力)
【テスト内容】
まず生成AI自身に「最適解」を出させ、次にその解を 自分で否定・再評価させるプロンプトを与えました。
例:
- 「この施策の最大の弱点は?」
- 「条件が変わった場合でも妥当か?」
- 「それでも採用すべきケース/すべきでないケースは?」
【評価観点】
- 最初の結論に固執しないか
- 表面的な言い換えで逃げていないか
- 条件付きで判断を反転できるか
【観測された違い】
- GPT-5.2 Pro:前提を明示したうえで結論を部分否定
- GPT-5.2:再評価はするが一貫性が弱い
- GPT-5.1 / Gemini 3:最初の主張を守ろうとする傾向
テスト③:赤入れ・否決回避(編集・最小修正力)
【テスト内容】
意図的に 「経営会議で否決されそうな4行要約」を提示し、
- 危険な曖昧さの指摘
- 否決される理由
- “最小限の修正”で通す案
を求めました。
【評価観点】
- 作り直していないか
- 情報を盛りすぎていないか
- 「この会議で何を決めるか」が明確になっているか
【観測された違い】
- GPT-5.2 Pro:「4行構造を壊さず、必要最小限だけ補正」
- GPT-5.2:改善はするが修正量が多い
- GPT-5.1 / Gemini 3:事実上の書き直し
テスト④:失敗前提のプロジェクト設計(失敗構造理解力)
【テスト内容】
成功条件を与えず、あえて
- 推進担当不在
- 研修参加率30%
- 経営層は流行目的
という “失敗が約束された前提”で、
- どう失敗するか
- なぜ失敗したか
- どこで軌道修正できたか
- 最小コストの復旧案
を求めました。
【評価観点】
- 失敗を偶然や人のせいにしていないか
- 分岐点が具体的か
- 復旧が現実的か
【観測された違い】
- GPT-5.2 Pro:失敗を構造化し、分岐点と介入策を提示
- GPT-5.2:概ね妥当だが粒度が粗い
- GPT-5.1 / Gemini 3:物語的説明に寄りがち
テスト⑤:全肯定リスクと期待値コントロール(期待値制御力)
【テスト内容】
生成AIが「完璧」だと誤解される状況を前提に、
- 誤解が生まれる瞬間
- それを防ぐ説明フレーズ
- あえて期待値を下げるべき場面
を整理させました。
【評価観点】
- 誤解の発生点を工程で捉えているか
- その場で使える言葉になっているか
- 合意文書レベルまで落ちているか
【観測された違い】
- GPT-5.2 Pro:型・テンプレまで提示。ただし正直すぎる場面も
- GPT-5.2:実用的だが網羅性が弱い
- GPT-5.1 / Gemini 3:説明は良いが合意に収束しにくい
※本評価は、同一条件・同一プロンプトで行った実務思考テストに基づく主観評価です。正解率やベンチマーク性能を測るものではありません。
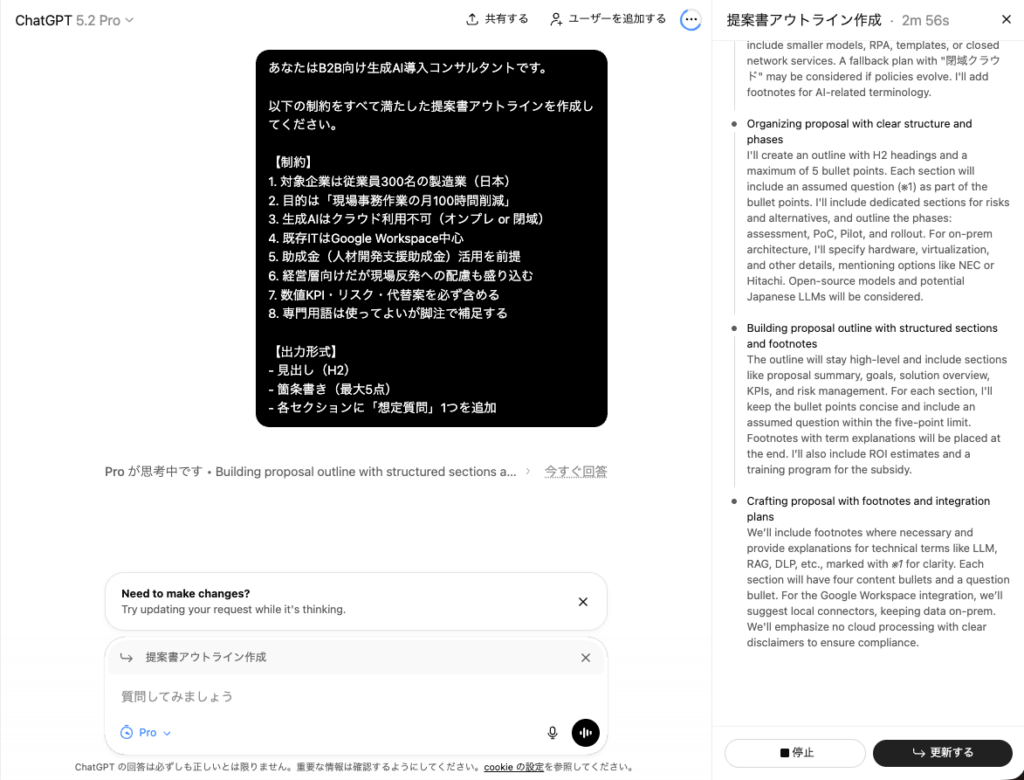
また、1点だけ追加でご紹介したい機能追加として、GPT-5.2 ProではGPTの思考プロセスを見て修正指示がしたい時に「更新する」を選択することで思考中でも指示が可能です。
今回の実験では使用していませんが、日常使う際には大変便利な機能が追加されています。
なぜGPT-5.2 Proだけが“別次元”に見えたのか
重要なのは、GPT-5.2 Proが「正しい答えを出した」ことではありません。
- 前提を忘れない
- 自分の答えを疑える
- ダメ出しを編集で吸収できる
- 失敗を構造として扱える
これらはすべて、コンサル・設計・レビュー・経営判断で必要な思考です。
言い換えると、GPT-5.2 Proは「賢い生成AI」ではなく、“壊れにくい思考をする生成AI”になり始めています。
一方で、期待値制御だけは満点にしませんでした。理屈として正しい説明はできますが、人間が行うような政治的・感情的な慎重さは、まだ人間の領域が残っています。
まとめ
ではGPT-5.2 Proは誰のものか、そもそも月額200$と高額なこともあり以下のように使い分けが必要です。
向いている人・業務
- 経営企画・新規事業に従事している人
- 全社導入・変革推進に従事している人
- コンサルタント
- 「考える仕事」をしている人
向いていない使い方
- 雑談・日常検索
- 軽いアイデア出し
- 最新情報の即時取得
別記事でまとめているように、検索は検索特化モデル、推論はGPT-5.2 Pro、判断は人間という役割分担が、現時点で最も合理的です。
つまりGPT-5.2 Proは、「すべてを解決するスーパー生成AI」ではありません。
しかし、実務で壊れない思考様式を初めて安定して示した生成AIであることは間違いありません。
GPT-5.2 Proの登場により、生成AIは「答えを出す道具」から「思考を共に進めるパートナー」であると改めて再確認させられたことでしょう。そしてその変化は、私たち人間側にも「どう考え、どう判断するか」を問い返してきます。GPT-5.2 Pro時代は、生成AIが賢くなる時代であると同時に、人間の思考力がより問われる時代になってきているのです。
writer:宮﨑 佑太(生成AIアドバイザー)