本記事を10秒でまとめると
来週登場が噂されているGPT-5.2は数学や科学で100%近いスコアを叩き出すが、買い物など日常タスクでは56%程度しか能力を発揮できない。「推論力」と「実用性」は別物であり、重要な情報は必ず検証し、難しい思考にはGPT-5.2、最新情報が必要なタスクには検索統合モデルなど使い分けが重要になる。
GPT-5.2の圧倒的なベンチマーク性能
X等でリークされているGPT-5.2のベンチマークをみると、他の追随を許さないような脅威的な数値を残しています。
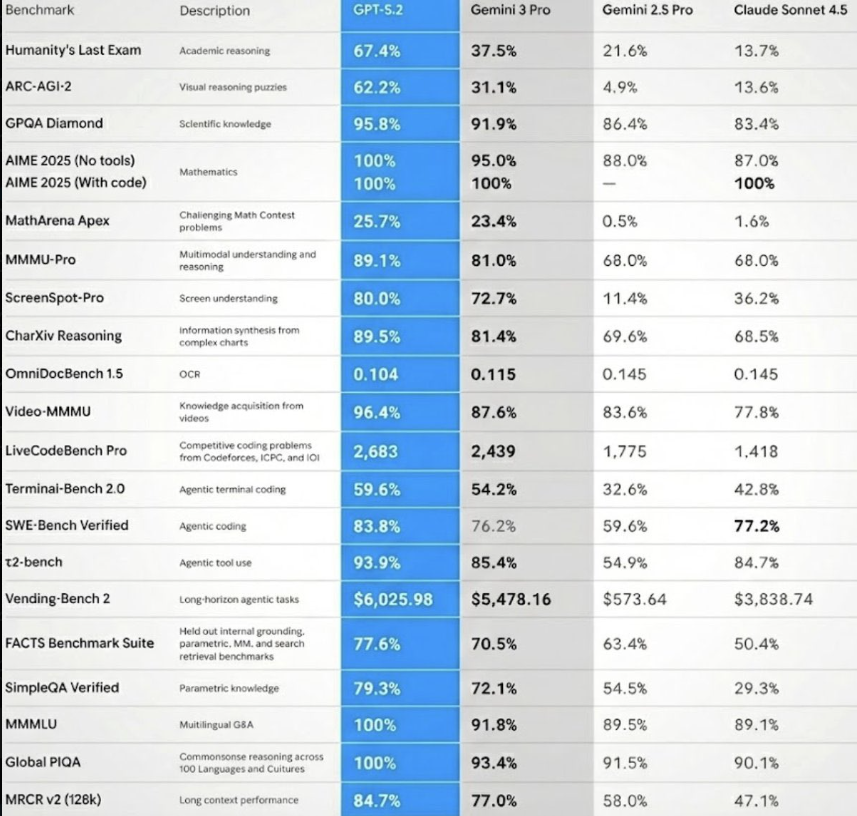
特に注目すべきベンチマーク
- AIME 2025 (数学): 100% – 確実な100点を達成
- Video-MMMU (動画理解): 96.4% – マルチモーダル理解でトップ
- Humanity’s Last Exam (学術推論): 67.4% – Gemini 3 Proの37.5%を大きく上回る
- LiveCodeBench Pro (競技プログラミング): 2,683 – 最高スコア
- Vending-Bench 2 (長期エージェントタスク): $6,025.98 – 2位の$5,478.16を上回る
これらの数字だけを見れば、GPT-5.2は「完璧な生成AI」に見えます。特に、数学、科学、プログラミングといった高度な推論タスクでは、人間の専門家レベルに達しているといっても過言ではありません。
このベンチマークだけを信じて良いのか?
ここで重要なのが、既存の生成AIベンチマークは推論やコーディング能力に焦点を当てていいますが、実際には多くの人が生成AIを買い物、料理、週末の計画など日常タスクに使用しているという事実です。
以前にコラムを掲載しましたが、ChatGPTメッセージの73%は仕事以外の用途で、これらの日常タスクでの生成AIの性能を測る体系的な方法は今までありませんでした。
参考:7億人のリアルを調査! ChatGPT、仕事の「便利ツール」と思っているのは少数?

このギャップを解消するのがACEベンチマークです。この新しいベンチマークは、買い物、料理、週末の計画、DIYといった日常的な消費者タスクでの生成AI性能を測定します。
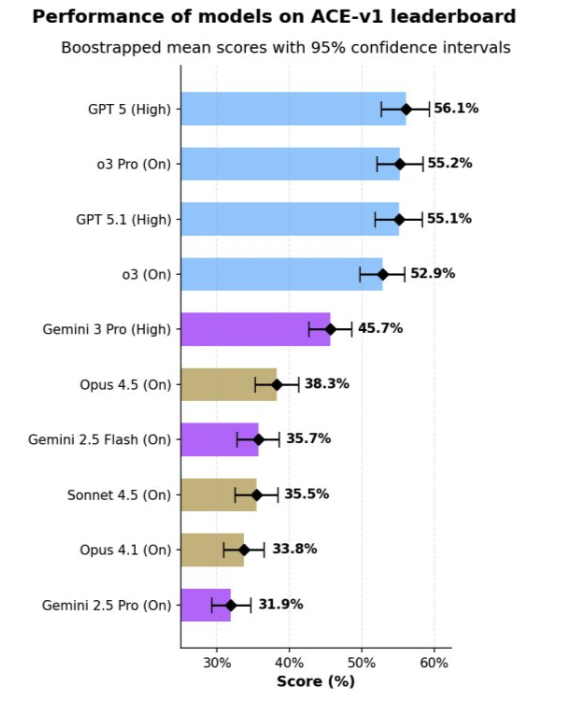
このACEベンチマークでは以下のような衝撃的な実用性の低さが現れています。
- GPT-5 (Thinking=High): 全体で56.1% – 「最高」でも半分程度
- ショッピングタスク: 最高モデルでも45.4% – 半分以下の成功率
- Gemini 3 Pro: 「リンク提供」で-54% – 存在しないリンクを自信を持って提示
- 価格情報: 多くのモデルが価格や製品情報をハルシネート(幻覚)
では、なぜこのようなギャップが生まれるのでしょうか。以下のような理由が考えられます。
- グラウンディングの欠如:
学術的な推論は「正解が一つ」ですが、日常タスクは「最新の正確な情報」が必要 - ハルシネーションのコスト:
数学で間違えるのと、存在しない商品リンクを提示するのでは、実害が大きく異なる - 検証可能性:
学術ベンチマークは検証が容易ですが、「このレストランは今日開いているか」といった情報は時々刻々と変化
GPT-5.2時代を予測する
GPT-5.2が正式にリリースされた場合、従来のベンチマークスコアはさらに向上するでしょう。ですが、日常生活を重視するACEのようなベンチマークでは劇的な改善は期待しにくいと予測されます。理由としては
- 推論能力 ≠ 情報取得能力:
いくら賢くても、リアルタイムの正確な情報にアクセスできなければ無意味 - ハルシネーション問題の根深さ:
これはモデルアーキテクチャの根本的な課題 - Web検索の統合精度:
検索を「いつ」「どう」使うかの判断が依然として不完全
おそらく、GPT-5.2のACEスコアは60-65%程度にとどまるのではないかと推測します。これは決して「劣っている」わけではなく、日常タスクの難しさを示しています。
では我々はどのようなモデルを使えば良いのか類する内容は以下のコラムでも書きましたが、タスクの性質でモデルを使い分けることが最重要です。
参考:【Gemini 3 Deep Think】並列思考で競合を圧倒する「考えるAI」の正体

ビジネス以外例えば、日常生活のリサーチなどでは検索統合モデル(ChatGPT / Gemini)を使用した後に出力を別のモデルでチェックさせるなど複数のモデルの使用が必要です。
- ステップ1: 情報収集 (検索特化モデル/エージェント)
Perplexity、Google Geminiなどリアルタイム検索統合が強力なモデル - ステップ2: 分析・推論 (GPT-5.2 / Claude Sonnet 4.5)
収集した情報を深く分析し、複数の選択肢を論理的に比較 - ステップ3: 検証 (人間 + 生成AI)
重要な情報は必ず一次ソースを確認し、価格、日時、在庫などは公式サイトで最終確認
まとめ
GPT-5.2が示す未来は、単一のスーパーAIがすべてを解決する世界ではありません。むしろ、多様な強みを持つ生成AIを、人間が賢く使いこなす世界です。
ACEが明らかにしたのは、生成AIの弱点ではなく、私たちが測定してこなかった能力の存在です。100点満点のテストで95点を取る生成AIは素晴らしい。しかし、日常生活で役立つのは、「今日」の「正確な」情報を提供できる生成AIかもしれません。
従って、賢いユーザーになるためには
- 盲信しない: どんなに賢いモデルでも、ハルシネーションは起こる
- 検証する習慣: 重要な情報は必ず一次ソースを確認
- 適材適所: タスクに応じてモデルを使い分ける
- 人間の判断を最後に置く: AIは強力なアシスタントだが、最終判断は人間が行う
これらを忘れずにビジネスでも日常生活でも生成AIを利用することが何よりも重要です。
GPT-5.2時代は、生成AIがより賢くなる時代であると同時に、私たちユーザーもより賢くならなければいけない時代なのです。ベンチマークの数字に踊らされず、自分のニーズに最も適したツールを選ぶ――それが、できるかどうかでビジネスのみならず日常生活のQOLも変わってくるかもしれません。
writer:宮﨑 佑太(生成AIアドバイザー)