本記事を10秒でまとめると
Googleが2025年12月にGemini 3に追加した「Deep Think」モードは、従来の生成AIが持つ「一本道の思考」を覆す並列推論技術を実装。
複数の仮説を同時探索・評価し最適解を導く「System 2推論」により、各ベンチマークで史上最高スコアを達成。月額249.99ドルの高額料金と処理時間の長さという制約はあるものの、AI推論技術における「大きな飛躍」として、複雑な数学・科学的問題解決の新時代を切り拓いた。
Gemini 3 とは
Googleが2025年11月に公開したこのモデルは、単なる“チャット向け言語モデル”を超えて、マルチモーダル入力(テキスト、画像、音声、動画、PDF、コード等)を統合的に処理できる、最先端の「汎用推論モデル」です。
主な特徴
- 高度な推論能力:複雑な論理展開、数学問題、科学的考察、プログラミングやデータ分析などにおいて、人間の専門家レベルに迫る性能。
- マルチモーダル理解:単に文字だけでなく、画像・音声・動画・PDF・コードを混在させた情報を同時に解析でき、異なる媒体間の関連性を踏まえた洞察や処理が可能。
- 大規模コンテキスト処理:最大で約100万トークンという広大な入力領域を持ち、大量ドキュメント・データ群・コードベースなどを一括で読み込み、包括的な解析や生成が可能。
- エージェント機能・実用性:「単なる質問応答」ではなく、多段階のタスク遂行、自律的なコード生成やデータ処理、複数ステップのワークフロー推進などを見据えた実務適用能力が備わっている。
つまり Gemini 3 Pro は、知識の検索や文章生成にとどまらず、「複雑で多様な情報を統合し、『考え』『処理し』『生成する』」ことを目的とした、現時点で Google が提供する最上位の「汎用 AI プラットフォーム」です。
今回のアップデートとは
従来のモデルはGeminiに限らず、どれほど高性能であっても、本質的には「一本道の思考」をたどっていました。質問を受け取り、学習済みのパターンから最も確率の高い答えを瞬時に出力する。そのスピードは圧倒的ですが、複雑な論理展開や多段階の推論が必要な問題では、しばしば浅い答えしか返せませんでした。
Gemini 3 Deep Thinkモードは、この限界を打ち破りました。
その核心技術は「並列推論メカニズム」です。Geminiが答えを出力する前に、複数の仮説を同時に生成し、それぞれを独立して評価・批判し、相互に比較した上で最も合理的な解答を選択する──この一連のプロセスを、内部で自律的に実行します。
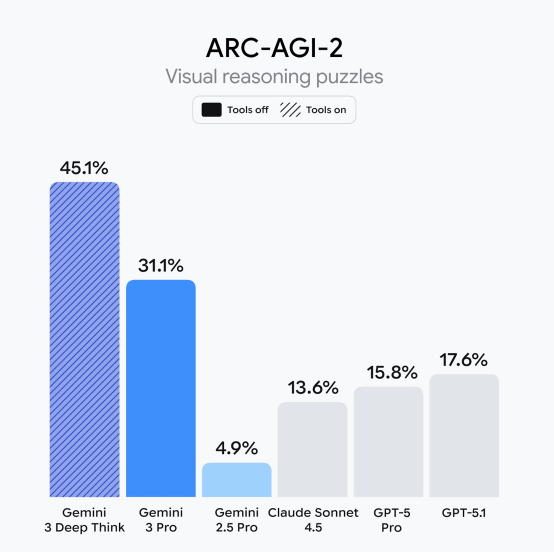
結果は数字に表れています。最も権威ある抽象的推論ベンチマーク「ARC-AGI-2」において、Deep Thinkモードは45.1%という史上最高スコアを記録。GPT-5.1の17.6%を2.5倍以上引き離し、Claude Sonnet 4.5の13.6%を3倍以上上回りました。さらに、2024年の国際数学オリンピック(IMO)では金メダル級の成績を達成し、人間の専門家レベルの問題解決能力を証明しています。
しかし、この技術革新には代償もあります。
Deep Thinkモードを利用するには、月額249.99ドル(約37,500円)という高額なサブスクリプション料金が必要であり、通常モードより処理時間も長くかかります。つまり、「すべてのタスクに最適」ではなく、「複雑な推論が必要な特定の問題に特化」したツールと言えるでしょう。
並列推論メカニズムとは
Googleの公式ブログによれば、Deep Thinkモードは以下のプロセスを実行します:
「Deep Thinkは、応答生成中に並列思考技術を自然に組み合わせる新しい推論アプローチです。Deep Thinkにより、Geminiは創造的に複数の仮説を生成し、最終的な答えに到達する前にそれぞれを慎重に批判的に評価できます」
具体的には:
- 複数の思考経路を同時生成
問題を受け取った瞬間、Geminiが単一の解答候補ではなく、複数の異なるアプローチを同時に探索し始める。 - 各仮説を独立して評価
それぞれの仮説が持つ論理的整合性、前提条件の妥当性、結論の信頼性を個別に検証。 - 相互に比較・検証
複数の仮説を並べ、どれが最も説得力があるか、どこに論理の穴があるかを批判的に分析。 - 最も合理的な解答を選択
最終的に、最も信頼性の高い解答を出力する。
この並列推論により、問題解決の効率が25%向上し、解決時間が短縮されることが報告されています。
Deep Thinkモードは、心理学における「System 2推論」(分析的・論理的思考)を実装しています。
人間の思考には2つのモードがあります:
- System 1(直感的思考): 瞬時に、ほぼ無意識に行われる思考。「2+2=?」のような単純な問題に最適。
- System 2(分析的思考): 時間をかけ、意識的に論理を組み立てる思考。複雑な数学の証明や戦略的意思決定に必要。
従来の生成AIモデルは、主にSystem 1的な思考──学習済みパターンからの瞬時の応答──に依存していました。Deep ThinkモードはSystem 2的な思考を実装することで、以下を実現しています:
- 思考予算の動的管理
Deep Thinkモードは、内部トークンパスの可変予算を割り当てます。つまり、問題の複雑さに応じて、回答前にどれだけ「考える時間」を使うかを動的に調整します。簡単な問題には少ないトークンで済ませ、難しい問題にはより多くのトークンを使って深く推論します。
- 段階的問題解決
複雑な問題を小さなステップに分解し、一つずつ解決していくアプローチを自律的に実行します。例えば、数学の証明問題であれば:
・問題の前提条件を整理
・証明に必要な定理を特定
・各ステップの論理的つながりを検証
・最終的な証明を構築
という段階を踏みます。
- 自己検証メカニズム
生成した解答を複数回検証し、論理的矛盾がないかをチェックします。これにより、精度が大幅に向上します。
- AlphaProofの統合──形式的証明の力
Deep Thinkモードには、Googleの数学的証明システム「AlphaProof」の技術が統合されています。AlphaProofは、形式言語「Lean」を使用した厳密な論理構造による証明を実行します。これにより:
・形式的な論理構築: 数学的に厳密な証明ステップを自動生成
・自動的な検証プロセス: 各ステップの妥当性を形式的に検証
・エラーの早期発見: 論理的矛盾を即座に検出
この技術により、Deep Thinkモードは2024年の国際数学オリンピック(IMO)で金メダル級の成績を達成しました。
ベンチマーク以外での実力差
ベンチマークスコアは技術的な到達点を示しますが、あくまで最適な状態でのスコアのためそのまま実務での使用価値とは言えません。ここでは、実際のコーディングタスクやビジネス環境での検証結果から、Deep ThinkとGPT-5.1、Claude Opus 4.5の実力差を、測定可能なデータで明らかにします。
違い1:タスク完了速度と反復回数の実測値
Redditのコーディングコミュニティで実施された実測テストでは、3つのモデルに対して実世界のコーディングシナリオ(指示遵守、コードリファクタリング、システム拡張)を与え、完了時間と品質を測定しました。
処理時間の実測結果:
| モデル | 3タスク合計時間 | 平均タスク時間 |
| Claude Opus 4.5 | 約7分 | 2.3分 |
| Gemini 3 Pro | 約10分 | 3.3分 |
| GPT-5.1 | 約12分 | 4.0分 |
Claude Opus 4.5は最速で処理を完了し、かつ最も高品質なアウトプットを生成しました。これは、「速度と品質のトレードオフ」という従来の常識を覆してOpus4.5が安定していると言えるでしょう。
さらに注目すべきは、反復回数です。エージェント型タスクにおける最適化達成までの反復回数を測定しました:
最適化達成までの反復回数:
| モデル | 反復回数 | 効率性 |
| Claude Opus 4.5 | 4回 | ベースライン |
| Gemini 3 Deep Think | 6〜8回 | 1.5〜2倍 |
| GPT-5.1 | 10回以上 | 2.5倍以上 |
Opus 4.5がわずか4回の反復で最適解に到達したのに対し、他モデルは10回以上の試行錯誤を要しました。これは開発時間とコストに直結する重要な指標です。
違い2:コード品質と完成度の定量評価
同じRedditテストでは、各タスクで「要件を満たした項目数」を10点満点で評価しています。
タスク別達成率(要件充足度):
| タスク | Claude Opus 4.5 | GPT-5.1 | Gemini 3 Pro |
| Test 1: 指示遵守(10項目) | 10/10 | 9/10 | 10/10 |
| Test 2: リファクタリング(10項目) | 10/10 | 9/10 | 8/10 |
| Test 3: システム拡張 | 最も完全 | 深い理解 | 最低限の実装 |
Test 2のリファクタリングタスクでは、Claude Opus 4.5のみが全10項目(セキュリティ修正、アーキテクチャ改善、型安全性、エラー処理等)を完全に満たしました。GPT-5.1は認証不足と安全でないDB操作を見逃し、Gemini 3 Proは一部のアーキテクチャ上の欠陥を検出できませんでした。
さらに、コード生成量にも明確な差が現れました:
コード生成量の比較:
- GPT-5.1: Gemini 3 Proの1.5〜1.8倍のコード量
- 理由: JSDocコメント、バリデーションロジック、明示的なエラー処理、詳細な型定義を含む
- Gemini 3 Pro: 最も簡潔だが「bare minimum(最低限)」の実装になる傾向
- Claude Opus 4.5: 適度な詳細度で、仕様が厳格なときは簡潔、包括性が必要なときは詳細に
GPT-5.1の冗長性は「防御的プログラミング」の表れですが、実務では過剰な場合もあります。Gemini 3 Proの簡潔さは迅速な開発に適していますが、プロダクション品質には追加作業が必要です。
違い3:トークン効率とコスト対効果の実態
料金体系だけでは見えない「実コスト」を、トークン使用効率から分析します。
公式料金体系(月額サブスクリプション):
| モデル | 月額料金 | 提供形態 |
| Gemini 3 Deep Think | $249.99(約37,500円) | Google AI Ultra専用 |
| Claude Opus 4.5 | $100/$200 | Proプラン/Maxプラン |
| GPT-5.1 | $20(Codex-max利用可) | Plusプラン |
一見、GPT-5.1が圧倒的に安価に見えます。しかし、トークン効率を考慮すると様相が変わります。
トークン効率の実測データ:
- Claude Opus 4.5: 中程度の推論effort設定で、従来モデル比76%のトークン削減を達成(VentureBeat報道、GitHub公式発表)
- Gemini 3 Pro: 複雑なシステムタスクで「思考時間」が長くなり、実コストが$1.68かかったケースあり(Opus 4.5の$1.10より高額)
- GPT-5.1: 標準的なトークン使用量だが、複数回の反復が必要な場合は累積コストが上昇
実コスト計算例(複雑なコーディングタスク):
あるシステム拡張タスクでの実測:
| モデル | トークン使用量 | 単価 | 1タスクコスト | 反復回数 | 総コスト |
| Claude Opus 4.5 | 標準 | 高 | $1.10 | 4回 | $4.40 |
| Gemini 3 Pro | 多(長時間思考) | 中 | $1.68 | 6回 | $10.08 |
| GPT-5.1 | 標準 | 低 | $0.80 | 10回 | $8.00 |
一見安価なGPT-5.1やGeminiも、反復回数が増えると総コストでOpus 4.5を上回ります。さらに、「開発者の時間コスト」を考慮すれば、Opus 4.5の一発完了は圧倒的に効率的です。
トークン効率が意味するもの:
Claude Opus 4.5の76%トークン削減は、同じ品質の出力をより少ないトークンで生成できることを意味します。これは:
- API利用の場合: 直接的なコスト削減
- サブスクリプションの場合: 利用上限到達までの余裕が増える
- レスポンス時間: トークン生成量が少ないため、出力が速い
実務での選択基準──3つのモデルの最適用途
これらの実測データから導かれる、実務での選択基準を整理します:
Claude Opus 4.5を選ぶべきケース:
- 初回で高品質なコードが必要(レビューコスト削減)
- エージェント型の自律実行タスク(反復回数が成否を分ける)
- プロダクション品質のコード生成(セキュリティ・アーキテクチャが重要)
- 長時間稼働する開発タスク(トークン効率が重要)
GPT-5.1を選ぶべきケース:
- 予算制約が厳しい初期開発フェーズ
- 詳細なドキュメント付きコードが必要(JSDoc、型定義重視)
- 会話的な対話で要件を詰めていくスタイル
- Microsoft Copilotエコシステムを活用したい場合
Gemini 3 Deep Thinkを選ぶべきケース:
- 複雑な数学・科学的推論が中心のタスク(ベンチマーク性能が最高)
- 迅速なプロトタイピング(簡潔なコード生成)
- Google Workspaceとの統合が必要な業務
- 100万トークンの超長文コンテキストが必要
重要なのは、「どのモデルが最強か」ではなく、「自社のタスク特性と予算に最適なモデルはどれか」という視点です。
Gemini 3 Proとの違い──使い分け戦略
今までの紹介を含め、推論能力の違いを中心にコストや時間などを考慮して以下のような使い分けをお勧めします。
通常のGemini 3 Pro:
- 高速で効率的な応答
- 標準的な推論能力
- 一般的なタスクに最適
- 即座に結果が必要な場合に適している
Deep Thinkモード:
- 時間をかけた深い分析
- 高度な推論と自己検証
- 複雑な数学・科学的問題に特化
- 正確性が速度より重要な場合に適している
使用シナリオ別の最適選択
| 用途 | Gemini 3 Pro | Gemini 3 Deep Think |
| 一般的な質問応答 | ◎ | ○ |
| 創造的なライティング | ◎ | ○ |
| 複雑な数学問題 | △ | ◎ |
| 科学的推論 | ○ | ◎ |
| コーディング最適化 | ○ | ◎ |
| アルゴリズム開発 | △ | ◎ |
| 迅速なタスク処理 | ◎ | △ |
| 形式的証明 | × | ◎ |
実務での使い分けのポイント
Gemini 3 Proを選ぶべきケース
- 時間が限られている: 会議中のクイックな情報検索、即座の意思決定サポート
- 一般的なタスク: メール作成、文書の要約、アイデア出し
- コスト重視: 通常の業務で十分な品質が得られる場合
Deep Thinkモードを選ぶべきケース
- 複雑な問題解決: 多段階の論理展開が必要な戦略立案
- 高度な技術的タスク: アルゴリズムの最適化、科学的分析
- 正確性が最優先: 法的文書の分析、財務モデリング
- 専門的な知識が必要: 研究開発、学術論文のレビュー
まとめ
Gemini3 Deep Thinkの登場により我々は今まで以上に「最高モデル」を使用するのではなく、「速度」と「深さ」のトレードオフを理解し、適したモデルを使い分けることが必要になってきます。つまり、タスクの分類をしなくてはいけないと言うことになります。
今すぐすべきこと:
- タスクの分類:
自社の業務を「即応性が必要なタスク」と「深い思考が必要なタスク」に分類 - ツールの使い分け:
通常モードとDeep Thinkモードの使い分け基準を明確化 - コスト対効果の評価:
Deep Thinkモードの高額料金に見合う価値があるタスクを特定
また、ベンチマークの結果からDeep Thinkモードは”専門家”の再定義を迫っているとも言えます。つまり、単なる知識の量ではもう生成AIに勝つことは難しく、「問題設定能力」「結果の検証能力」「創造的な問いたて」でしか差がつきません。
これらこそが生成AI時代に必要な真に価値のあるスキルではないでしょうか。
「考えるAI」を使いこなすために、我々ユーザーこそが「何を考えさせるべきか」を考えなくてはいけない時代になりました。言い換えると、広い意味で思考力こそが今後の市場価値を左右するため、全ての団体 / 個人がこの力を高めていく必要があります。
writer:宮﨑 佑太(生成AIアドバイザー)